

原理什么的,都还算比较简单,其中一部分可以归类到任意setter/getter调用这一块
环境准备
java环境是jdk8u66的pom.xml
1 |
|
简单测试
对于getter调用的验证
1 | public class SnakeYamlTest { |
运行结果如下
对于setter调用的验证
1 | public class SnakeYamlTest { |
运行结果如下
调试分析
JdbcRowSetImpl链
在本地起个ldap服务,这里是得到了可利用地址: ldap://127.0.0.1:1389/prb171
之后开始着手分析,用到的测试类如下,我们在yaml.load下个断点开始分析
1 | package org.example; |
跟进一下发现是一些重载,我们盲跟两步,在loadFromRead中的289行打个断点,之后的流程以这里为起点跟进

getSingleData的源码如下,简单分析一下,这块是先从我们所传入字节流中读取单个节点,之后再对该节点进行一系列判断,先判断当前节点是否为空,再判断当前节点是否为Java对象,最后再判断当前节点是否为根节点。不过这里面只有第一个判断是比较关键的,剩下两个判断不影响我们走到113行把节点转换成Java对象这里,我们跟进一下113行。

越过重载跟进到一个挺长的三目表达式这里,判断的对象是this.constructObject。这个对象简单地介绍一下,这是SnakeYaml为已加载过的对象所设的存储表,这块相当于是在进行一个缓存判断,因为表中没有我们本次要加载的对象,我们这里跟this.constructObjectNoCheck(node)
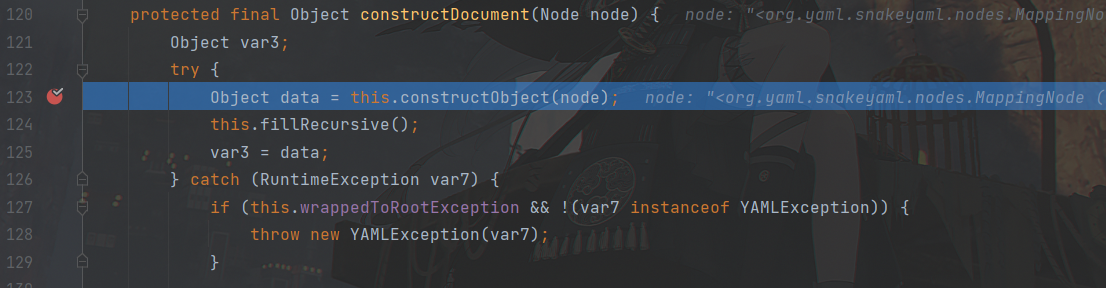

跟进之后,这里会先判断当前节点是否为自递归节点,如果不是的话就把当前节点加入this.recuresiveObjects里,然后再进行一个缓存判断,如果constructedObjects属性中存在与当前节点对应的Java对象,则返回该对象。如果不存在,则调用constructor.construct方法构造Java对象,我们这里是跟到了constructor.construct()这里。
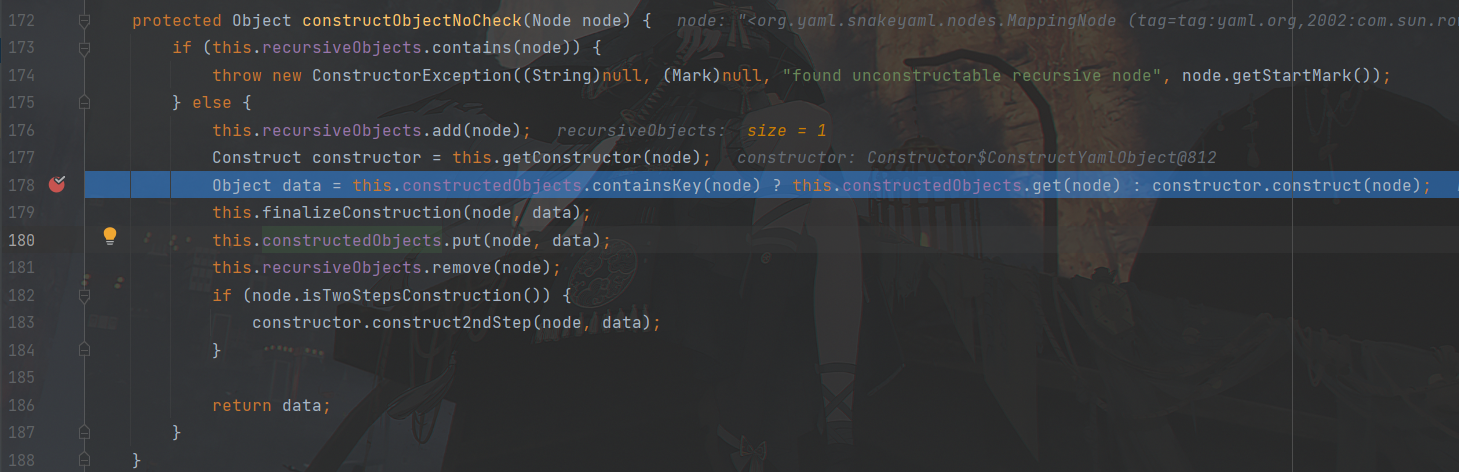
跟进一下之后发现是个重载,根据node的类型来指派构造器,这里是指派到了ConstrucMapping类型的,我们跟进一下它的construct方法。


在该方法里,会先将当前节点类型强转为MappingNode,之后再判断该节点的父类是否为Map,Collection中的任意一种。因为这里都不是,我们最终使用刚才获得到Constructor.this.newInstance()来实例化我们的JdbcRowSetImpl对象,而在474行则再会对我们的node进行判断,判断这个节点的实例化是否是那种可以一次完成的类型,如果确实是,则直接返回刚才生成的对象,如果不是,则用this.constructJavaBean2ndStep()进行第二次构造,我们这里还得再跟一下。
我们的终点在这个506行起头的try结构上,在这里面,他会有一个反射调用属性的set方法的过程。490行这里会对node下面的子节点进行constructedObjects的
遍历展开,分析起来有点麻烦,咱们就不详细跟进了,直接往后走流程。

$i 是长这个样的,这里先从keynode中获得key,再根据key的名称获得属性对象,之后如法炮制获得value,最终在经过一系列判断之后,再property.set()中经过反射实现set方法的调用,到此为止SnakeYaml部分的东西就算结束了,我们再象征性的往后分析一下JdbcRowSetImpl链的部分。


第一个property是dataSource,跳过一堆反射步骤,最终调用的是setDataSourceName,最终通过父类的setDataSourceName()方法,把DataSource的值给安排妥当了。
第二个property是autoCommit,最终调用的方法是setAutoCommit 。setAutoCommit这个方法里最关键的地方在于4067行调用connect()这块,我们跟进一下。

一点进来就能发现try 结构里面躺着的 lookup调用点,到此整条链子也就收工了。

ScriptEngineManager链
SPI机制
当服务的提供者提供了一种接口的实现之后,需要在 classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体实现类。当其他程序需要这个服务的时候,就会找到接口文件里面的实现类并且将之实例化,因为这里的实现类可能不只有一个,所以我们经过加载得到的往往是一个迭代器。
比如在加载mysql-connector-java-8.0.27.jar的时候,会自动找到其下目录的META-INF/service文件夹的文件,之后再根据文件中所记载的类名进行类加载,也是这个机制的原因,我们不用手动加载驱动(老版本就得手动加载),直接获取连接即可。
在我们的JDK 中,这里查找服务的实现的工具类是 java.util.ServiceLoader,一个基本的SPI机制使用的Demo如下
1 | // 定义服务接口 |
流程分析
前面的流程和JdbcRowSetImpl链差不了太多,顶多是constructor这里会有些许不一样,我们这里从construct这里开始跟就可以了。


先瞅瞅node的结构是怎么样的,然后再来分析源码。能够看出来,这里是根据value的大小,设置了一个可能会起到作用的构造器数组,之后又根据当前node本身设置了一个构造器数组,总共两个,一个针对value里的部分,一个针对当前的ScriptEngineManager


之后把重心放到我标断点的地方,能够看到这里会先将当前node的value大小和当前node的constructor的参数类型个数做比较,如果相等,则将当前的constrcutor放到possibleconstructor数组里。在以147行为起点的代码段会对snode进行遍历,用constructObject以递归的形式实例化出snode里面的参数。
这块实例化的顺序是 URL(String) ->URLClassLoader(URL[]) -> ScriptEngineManager,我们跟进一下ScriptEngineManager的newInstance这里。



调用了ScriptEngineManager的单参构造函数进行初始化,这里随着图示断点跟进几步来到了getServiceLoader()这里,感觉是关键,跟进去看看。



发现是这么个样,和我们上面给的demo差不多,些许不同的是这里自己指定了类加载器,也就是我们之前所设的URLClassLoader来加载ScriptEngineFactory接口的实现类,不过因为这里是SPI的底层其实是懒加载的模式,并不会在此就把类给加载出来,而是在迭代的时候再进行加载。所以我们要步出回到initEngines()继续分析。
还是和基本demo那里给的差不多,先是通过sl获得一个迭代器,看了下官方文档的解释,这个迭代器里面的hasNext()就是懒加载实现的地方,首先会到providers中去查找有没有存在的实例,有就直接返回,没有再到LazyIterator中查找,我们接着步出往下跟。


在120行就调用了hasNext(),跟进后调了调,开始了懒加载(预设置部分),这里接着跟进

跟进hasNextService()
根据前缀和serviceName拼接得到加载位置,在348行这里,会根据我们所指定的位置,读取实现类的信息,我们步出往下看
跟进itr.next()这里,这里没什么需要特别分析的,基本是刚点进去就得跟进,最终实在nextService这里实现了类的实例化。


最终运行结果如下